I gave a 25ish-minute talk at PyCascades 2022 covering a Django app that Jamey Sharp built and I supported for the Portland GDC. My script and slides are below. Please note that this is not an exact script; I had to cut some material from my talk during recording to get it closer to the time limit that I’ve left in this version of the script. Consider it a little bonus material! You can watch a video of the talk on YouTube or below:
I’m here to talk about my experiences doing bail and legal support for protestors arrested in 2020 and 2021 during the George Floyd Uprising. Since I’m White and I’m talking about supporting people arrested while asking for racial justice, I need to say that I’m only talking about the specific project I worked on. I didn’t organize or lead protests or anything like that. Please consider this a report back on the small chunk of mutual aid that I worked and nothing more. Furthermore, I did not do this work alone. This talk covers the efforts of dozens of people who I am proud to work alongside.
This talk covers technical topics, but it also includes discussions of institutionalized racism and police violence. If you’re not in a place where you can hear about these topics, please consider stepping away for the moment. You can always watch the recording later.
On May 25th, 2020, George Floyd went to a grocery store in Minneapolis and made a purchase. Thirty-one minutes later, he was dead at the hands of a police officer.
On May 26th, hundreds of protestors took to the streets in Minneapolis, demanding accountability for Floyd’s death — and the long list of other deaths of Black people at the hands of police officers.
On May 27th, a small group of Black and Indigenous women gathered in Portland at the Multnomah County Justice Center to hold space in memory of Floyd.
On May 28th, around 100 people gathered at the same building, with some people sitting in the doorways. Riot police violently pushed people away from the building.
On May 29th, over 1,000 people gathered at Peninsula Park in North Portland and marched into downtown to gather again at the Justice Center. Portland police officers arrested 13 people.
The Portland General Defense Committee immediately started posting bail for protestors who were arrested. The GDC started as a legal defense organization for union organizers and workers. Members of the Industrial Workers of the World founded the GDC in 1917. The Portland branch started in 2017 and has provided jail and legal support to protestors since its start. We did the same things for folks arrested on May 29 that we did for past protests: We made a spreadsheet of people arrested and started figuring out who needed bail money, including prioritizing arrestees by relative risks at the jail. Those risks included whether the person arrested was Black or Indigenous, LGBTQ, or had health risks.
Dealing with thirteen arrests at once was a stretch for us. At that point, we were used to two or three arrests at one event and supporting maybe two people with ongoing cases at any given time. We were able to pull together bail funds from members and friends, but we knew we would need to raise money to cover legal costs and reduce the bail burden we’d already taken on. Prior to 2020, the Portland GDC had a budget of a few thousand dollars per year. I put up a GoFundMe early on May 30th. By the end of that day, police had arrested 64 people.
Protests continued every night into January 2021. I’ve heard estimates that 70,000 people participated over those eight months. Portland still sees several protests and rallies around racial justice every month. Local police and federal law enforcement agents made over 1,000 arrests at protests in Portland. They beat, gassed, and otherwise hurt countless protestors and journalists.
As you can guess, gathering and managing information on who had been arrested, who needed bail money, and where each person was in the legal process outgrew a single spreadsheet rapidly. On June 6th, 2020, I contacted on Jamey Sharp, who I knew from various tech-related things here in Portland and asked for help. I was deep in the weeds at that point and basically gave Jamey free rein to figure out how to replace this terrible spreadsheet with something that could manage information better. We were not in a position to pay Jamey and I am eternally grateful he was able to help us. The Portland GDC still has minimal resources beyond dedicated volunteers and some funds earmarked for legal expenses. While we eventually raised over a million dollars, that money is all for to bail and legal expenses and therefore not available for administrative costs like building software applications.
One of the reasons I reached out to Jamey is because of his experience scraping all kinds of websites. He was unable to speak at this event, but I encourage you to check out his project Comic Rocket at comic-rocket.com, which is one of the places he got that experience. I figured Jamey would be able to automate some of our information gathering, letting volunteers focus on things technology can’t do. Jamey’s experience meant that he had the first iteration of our app up and running on June 12, with all the notes in our terrible spreadsheet imported and ready for us to work on.
As the summer of 2020 wore on, we added users and functionality and scaled up a little just about every day. The Portland GDC’s workflow constantly changed based on capacity and the growing number of arrests. This was not a situation where a developer got to make nice neat little upgrades and slowly roll them out to users. This was duct-taping steering to an airplane that was already in flight and occasionally doing barrel rolls.
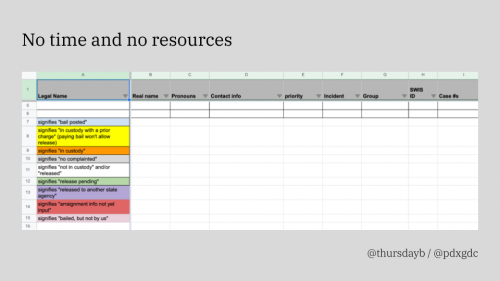
The web app we use for the Portland GDC’s work can be thought of as two key pieces. Most people only ever see an interface to a database, listing people who were arrested with a bunch of fields about their contact information, the status of their court case, and various other details. It’s an amped-up, search-friendly spreadsheet.
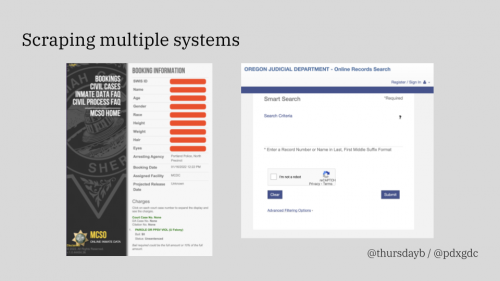
But the app also pulls in information from several sources, automatically prepopulating many of those fields and providing updates to volunteers. Those sources generally don’t have APIs, so the app scrapes them. The sources include Oregon state court records and jail records from the Multnomah County Sheriff’s Office. MCSO is responsible for processing anyone arrested on state charges and many of those arrested on federal charges in Multnomah County (which includes the majority of the city of Portland).
The information we need to do our work comes in an absurd variety of formats, with an equally absurd set of access requirements. For instance, a lot of court information is in PDFs that are scans of printed documents, often with important handwritten notes like “Dropped” to indicate a suspended charge.
Federal courts work differently than state courts. and have less public information that can be scraped. Federal court cases go through PACER, which is an app that charges 10 cents per page when you access a document, as well as fees for search results and non-case specific reports. 18F, the federal government’s in-house technical consultancy, has looked at upgrading the system but their report is best summarized as no one knows how PACER works, it’s unmaintainable, and we need something entirely new and built from scratch.
Important information also disappears regularly. MCSO’s arrest information will change with no warning and no record if someone at the jail updates information, including during the booking process. Records of arrests drop off the site entirely after a few weeks. There’s also no listing of citations — incidents where protestors are charged with a crime, usually a misdemeanor, but not arrested. And the information is available is often full of errors. Information collected during arrests is the worst. We’ve known for a long time that law enforcement agents will “tweak” certain information they collect to make their own stats look better. But the data we saw from protests made those changes much more obvious. Police record the races of people arrested incorrectly constantly. In particular, we’ve seen glaring errors around the race of people of color, which have allowed the Portland Police Bureau and other agencies to claim that almost all protestors arrested in Portland are White. We’ve also seen names, genders, physical descriptions, and more recorded incorrectly.
We’ve had to figure out the meanings of certain data through trial and error because there’s not any documentation available. MCSO also uses different terms and definitions for specific charges than the Oregon court system uses, to the point that our app only grabs the statute number a person is charged under and maps it to correct charge information in our database.
This system is especially infuriating when you realize that it’s on the people who are arrested to correct any errors. Since errors can have consequences that include being kept in jail, they can be impossible to correct without expert legal help. People who are arrested are also expected to stay up to date on their cases, without any of the modern notification systems you might expect. If someone’s charges are suspended, that person is instructed to call the district attorney’s office at least monthly to check if their charges have been reinstated for at least the next two years. If they don’t, they’ll likely miss a court case which will result in a warrant being issued for their arrest and other terrible outcomes. COVID has also meant that policies change constantly, often without online notice. Even before the pandemic, details around court hearings routinely changed on the day of, but as things moved online, everything about legal processes got more complicated.
These websites are also delicate. Some were constructed by contractors trying to keep costs down, while others are built by companies that know that they can take advantage of people who are incarcerated without anyone important caring.
Django and Python were the logical choices for this project for a few reasons: First, Jamey had already built Django apps and was pretty familiar with the framework. And while I haven’t built a whole Django app by myself, I’ve gone through some workshops. Second, Django’s built-in admin interface makes managing a bunch of structured data really easy. The user interface enables anyone to edit that data without tons of training. Jamey was also already familiar with Scrapy, a Python scraping framework, so he could get that set up with a Django-based app quickly.
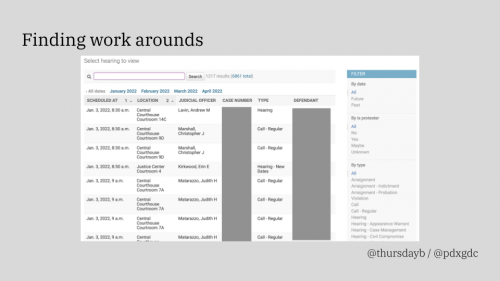
One of the pieces of information we need to grab automatically are upcoming court dates. The Oregon court calendar site is particularly irksome. Jamey jumped through lots of programmatic hoops to get that scraper running: the site limits search to 550 results, without offering any “next page” button. The scraper can’t just grab all calendar entries over the next 3 months without hammering the site harder than we want to. So the solution is a little complicated: the scraper looks at the specific case numbers we care about, then groups all the cases with the same starting numbers, trimming off the last two digits. When the court calendar is queried with those truncated group numbers, there are a max of 100 active cases returned. By batching together cases, the scraper minimizes the number of queries — though Jamey has pointed out that if whoever designed the court calendar site had just limited to search results to 1,000 rows instead of 550, he could have cut the number of queries even further.
Of course, there’s still plenty of work that requires a human touch. We have to audit our data regularly, adding in pieces that MCSO missed or that come from conversations with the protestors we’re supporting. Django has made those audits relatively simple, even though they still require a lot of reading through information for the humans involved. We can use tags for indicating the specific categories that need auditing at a given time, as well as sort and filter information in a variety of ways.
The Portland GDC is not a large organization, even now. We’re also not an especially technical group. We recruited volunteers to work on legal support in July and August of 2020, and more volunteers have joined since then.
In preparing this talk, I asked folks who use the app regularly what technical knowledge they had before volunteering with the GDC. The range was even wider than I expected. One of our most technical volunteers (other than Jamey and myself) came in knowing some JavaScript and could use the command line. But we also had folks with very little technical experience, who might use Google Docs or email, but not much else. With some onboarding and documentation, they were all able to make use of the app, as well as suggest improvements that would make our work easier.
All onboarding, and all other work for that matter, happens remotely. Django’s user interface is reasonably simple right out of the box and while we’ve tweaked the user experience lightly, Django uses a visual language in interfaces that is very similar to what’s considered “standard” on the internet.
I created our technical onboarding process. Another person was responsible for walking new folks through specific support situations, communication norms, and our policies, so I was able to focus just on getting people on to the app.
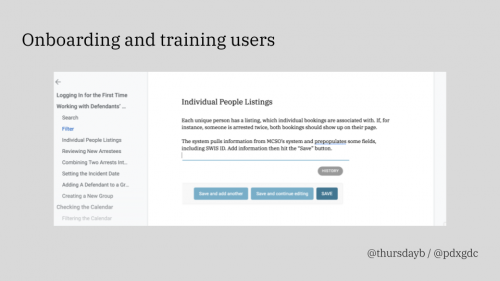
I do a video call with each new user that includes a 30-minute walk through of the app. We actually don’t always need the full 30 minutes, but we set up user accounts during that session and getting folks through their first time logging in was often hard — in fact, it was the point our users struggled with the most. That’s because some of our account setup emails wind up in spam. So I built in time to search around for emails. I also limited onboarding sessions to a max of three new users because I only have enough patience to go through three people’s spam folders at a time.
During the walk through session, we go through each section of the app as well as our documentation. Our documentation is a shared Google Doc with screenshots and written descriptions — it’s not fancy, but it does contain answers to basically every question anyone has asked me about the app.
We tweaked the app as users asked questions and needed more features. Jamey wisely pushed back every so often and reminded us of our options, even deleting certain features when they were no longer needed. If Jamey hadn’t provided a technical voice of reason, we’d probably have a full-featured CRM at this point, even though that’s not what we need.
And when I checked in with our users while getting ready to give this talk, they told me that the app was intuitive, friendly, hard to break, and empowering. Users felt empowered to work with data, even if they didn’t come in knowing tech, legal proceedings, or activism. Some features still don’t get used as much as possible. But volunteers say this is more about the time available to do work, not due to difficulties with the app. People also like that they don’t feel beholden to the app and that it’s not judgmental about unfilled fields. One person even said that using the app reminds them of using a message board because they can see the notes and work of other volunteers, which helps them stay connected through all this remote work.
We realized early on that we were sitting on a pile of valuable information. While most of what we pulled together was publicly available, it wasn’t combined in this way anywhere else. Between what we scrape and the information we add from the people we’re supporting, we created a doxxer’s paradise. Not only do we have data like physical addresses and phone numbers, but we also have notes on who needs what kinds of help. The risks of holding this information are massive. If someone with bad intentions got access, they’d be able to easily harass people both online and offline. We have an ethical obligation to mitigate every risk we can and to protect this information. The alternative is compounding the harm legal systems are already doing to folks.
We also faced a lesser risk of losing access to the sources where we pull information from. That did happen several times — not only does MCSO remove information from their arrest records, but the Oregon court system stopped allowing access by anything with an IP address located outside of the US, which coincidentally enough included us at the time. Jamey found us work-arounds, but I’m always waiting for the next time one of these systems changes their access controls. We also faced concerted attacks on any tool we publicly use: we dealt with numerous malicious reports to GoFundMe, Twitter, our email provider, and more.
We reduced our risks in several ways. First off: we obviously didn’t go around telling people about this app. After all, if someone is attacking your email, they’ll attack every other system they can find related to your organization. We’re facing less attention online now, so talking about the app here is a calculated risk that we’re comfortable with — but I’m not telling you who hosts the app or other important details to keep those risks to a minimum.
We also look closely at everyone who gets access to the app. Our due-diligence process for volunteers includes an in-depth internet background search and confirmation of the information we find with shared connections where possible. Jamey was also able to set up multiple types of user accounts so that we could limit each volunteer’s access to information they actually need to do their work. If, for instance, someone is writing letters of support to people who are currently incarcerated, they can only see those people in the system who they’re writing to. Those volunteers don’t get much more than an address and some biographical information.
Technical security is, of course, an aspect of risk mitigation. Django has good security features out of the box, assuming you use them. By using Django, we could use built-in security options and also access documentation that we could adapt to explain what was going on behind the scenes to volunteers. But the most important step to managing our security concerns was our effort to avoid collecting information that we didn’t feel we could protect — and that policy would have been the same no matter what framework or language the app was written in. No technology choice is as important as defining what data you’ll collect and how it will be handled.
One of our biggest ongoing issues was burn out. Basically everyone burnt out over the course of 2020 and 2021 — doing legal support just made us burn out faster. We’ve had higher turnover among volunteers than I’d like, but this is hard work. Even though we don’t need to worry too much about gathering and processing data, we’re dealing with emotional situations and even the best outcomes for the people we’re working with involve lots of time dealing with an adversarial legal system.
The only way to handle the fluctuations in capacity is to document EVERYTHING. Everything that happens in an individual case gets recorded in the app. Everything about the app gets documented, too. Our documentation isn’t fancy: it’s a document that I add questions and answers to whenever an app user asked me something. I lifted some pieces out of the Django documentation and reworded them a bit to ensure our users understood how to handle a problem even if they didn’t come in with a ton of technical experience. And any time an edge case came up, I took tons of notes.
I did worry a lot about what would happen when Jamey and I burned out, however. We both managed to hang on until the app was basically stable and there hadn’t been any new features needed in a while. I did want to make sure that someone had enough knowledge to at least decide if a situation was an emergency and to have someone who could step up if such an emergency came to pass. Luckily, our most technical volunteers reached a point with the app where they seemed capable of handling questions and I drafted a back-up developer who would be willing to handle emergencies before I had to take a break.
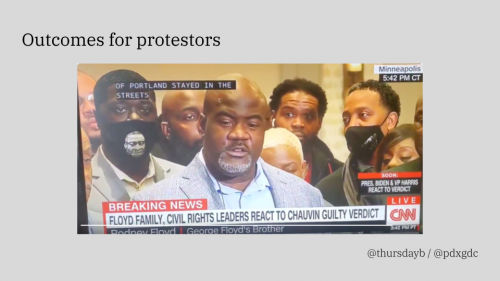
I think the work I’ve done with the Portland GDC over the past two years is some of the most important work I have done or will do. We put together legal support for hundreds of protestors out of Django, duct tape, and donations from strangers. We did our part to ensure that protestors could be in the streets for months on end and reduced the risks they faced. One of the most meaningful measures of our work, at least for me, is that Rodney Floyd, George Floyd’s brother, thanked Portland protestors specifically last April. He said the support of protestors meant so much to their family and that staying in the streets helped ensure his brother’s killers faced justice.
So here’s where everything stands as of February 2022: Mike Schmidt, the district attorney here, suspended most protest-related charges. That’s not the same thing as dropping charges entirely. Instead of dropping charges, he’s just not currently prosecuting charges. The DA has the option to reinstate suspended charges for years to come. He’s already reinstated a few. By suspending charges, rather than dropping them, the state also gets to hold on to bail money and evidence until the charges age out. And since almost $700,000 of the money the Portland GDC raised went to posting bail for hundreds of protestors, that money is not available for legal fees or bail for future protests for an indeterminate amount of time. Schmidt is considered a very progressive DA and he’s still chosen to hold protest-related charges over protestors’ heads for years to come.
The federal district attorney, Scott Asphaug, hasn’t been so nice. Several protestors are facing federal charges, with Black and Indigenous folks facing the harshest penalties. There are at least three such cases which will be going to court in the next few weeks with each defendant facing years in jail. It’s also worth noting that Asphaug previously worked for the Portland police union to get police officers out of trouble during internal investigations and the U.S. Department of Justice does not consider that relationship a conflict of interest.
The city of Portland, as well as several federal agencies, are facing lawsuits from many of the protestors who police attacked. Residents of Portland who were not involved with protests but were teargassed or otherwise harmed are also bringing their own lawsuits. While a few cases have already been settled with payouts by the relevant government agency, many seem to be going to court.
While Portlanders are no longer protesting in the streets every night, cases related to the George Floyd Uprising won’t be over for months, perhaps even longer. The Portland GDC is still doing legal support and expects to be doing prison support for folks unjustly incarcerated over these protests for years to come.
I hope you found this talk valuable, both in terms of learning about launching a Django app with minimal resources and even less time and in terms of understanding the amount of work it takes to support protestors through arrests and court cases. The Portland GDC continues to support people arrested at protests in 2020 and 2021 and if you’re able to, please consider donating to help cover the legal costs that many protestors are still dealing with. You can donate through CashApp, Venmo, or by mail to PDX GDC, 2249 East Burnside Street, Portland, OR 97214.
As someone who regularly submits talks to technical conferences that aren’t really focused on technology, I found the feedback from this proposal especially helpful for future talks. Here’s one highlight that has convinced me to double-down on writing lengthier proposals in order to get my idea across:
Audience:
We especially liked the ‘audience’ section. The description of whom the tutorial was aimed at was excellent.
Most of our favorite proposals include clear learning goals (showing us what the audience will learn, and giving them motivation to attend). This one provides additional details, unique to the format of the tutorial itself:
“Attendees will have at least one writing sample they can share and will be better equipped to write and test their own materials, as well as evaluate others’ writing. They’ll also know about opportunities to share their writing with other pythonistas.”
I hope these materials serve as an inspiration for Python speakers, especially anyone considering putting in a talk that focuses less on the programming language itself and more on the context in which we use it.
And if you need ideas for topics that would make great talks in 2022, here are a list of ideas pulled from various Twitter threads I’ve posted over the years and updated as needed (2021, 2020, 2019, 2018). These talk ideas are, of course, not vetted by PyCon staff and are just talks I want to watch.
Most of us have spent almost two years thinking about COVID vaccines almost constantly. Some places have done well at distribution, some are struggling. If you’re building or using Python tools to help with the vaccination effort, tell the rest of us. If there’s still work to be done, tell us about it so we can help.
If you have any scripts or tools that make living a socially-distanced life easier, I think a lot of people are still looking for ways to make remote everything easier.
A talk about writing Python with minimal internet access or writing programs for users with minimal internet access may seem like a counterintuitive idea. But many folks have precarious internet access, and the continuing pandemic leaves those folks with fewer opportunities to go elsewhere for better access.
I’m not sure what the highest number of types of pythons you can reference in one talk, but I’ve seen some herpetology tools written in Python and there’s a giant prehistoric snake with the taxonomic name _Montypythonoides riversleighensis_. There’s a lot of material there.
Was there some nuance about Python you struggled with this year? Write up an explanation — I promise that if you struggled with a Python concept, some other Pythonista has too!
Are you working on one of the many elections happening in 2022? Empower your fellow Python programmers to take their skills and get involved in the political process.
We need to talk about prisontech and how much technology works goes into maintaining white supremacy if we want to have even a chance of reducing structural racism.
Las PyCon Charlas será un track de charlas en español abierto a toda la comunidad que tendrá lugar en la PyCon US. Si hablas español, ¿por qué no envías una propuesta de charla?
With the current wave of unionization at a variety of tech companies, it’s time to talk about organizing in tech communities. Some folks may be starting out with collective action, so both introductory talks and more advanced materials are good.
This is more a general topic for programmers, rather than just Pythonistas, but how about a talk on dealing with old computer hardware. Programs like Portland’s Free Geek do phenomenal work getting technology in the hands of those who need it, like students going to school remotely.
As responsible consumers of data, why do we not talk more about how we dispose of data? Storage space may not be an issue, but privacy definitely is!
Programmers need more education on how to mitigate climate change factors. Honestly, all I know off the top of my head is that Bitcoin produces more carbon emissions than the entire country of Argentina.
What do you do if you discover that your employer provides, say, a connected thermostat to a client you don’t like, for instance, ICE? Holding employers to ethical standards is a skill set every programmer needs.
There are Python newsletters, podcasts, blogs, books, and other media. Maybe it’s time to start talking about the Python media ecosystem. What would this talk look like? a guided tour through what’s out there? a discussion on how the different bits interact? There are so many options!
Based on unfortunate mistakes that were made, possibly at my desk, I’d love to hear more from experienced folks on how to interact with other people’s projects in ways that won’t overwhelm a server or break other stuff. i.e. how to use an API run by a nonprofit with an all volunteer tech team.
Fundraising for open source projects has changed dramatically in the last two years. PyCon, for instance, is usually the PSF’s main fundraiser. If you’ve successfully raised money for an open source project in the last year, we’d all appreciate you sharing with the rest of us.
I have a dream of PyCon hosting its own fashion show some day. We deserve it. And Nina Zakharenko’s earrings deserve to be on the runway.
What’s the absolute weirdest hardware you’ve gotten Python to run on? Currently, I think the Furby is a standout but I bet y’all can surprise me.
If you struggled to learn any concept related to Python, consider giving a talk about that concept — I can guarantee that if you struggled with something, other folks in the Python community struggled too!
I’ve seen dozens of tarot and astrology apps at this point. Getting a developer’s perspective of building systems that (I assume) need to work in an element of chance or intuition world make for an amazing talk.
I’m getting kind of tired of talks on automation scripts for businesses. How about some household automation scripts? Did you write a script for generating a shopping list or managing chores?
Have you tweaked Python IDEs & other programming tools to make programming in Python accessible? In the past, talks covered tools for programmers with low vision and teaching Python in ASL, but there must be other accessibility hacks worth sharing.
I have seen some truly amazing Python-driven sensors for temperature, moisture, and other environmental factors. I have to believe someone has put them all together into an amazing gardening system. If you are that person, you should tell the rest of us how to do the same!
I’ve heard more than once that Python is used on every continent, but what exactly are Antarctic Python users up to? That’s a talk I’d listen to, for sure!
I think every conference organizer has seen several versions of “How to make your first contribution to open source”, so it’s time for talks about how to make your second, or third, or hundredth contribution to open source. Tell us what comes next.
There are plenty of talks out there about programming with security in mind, but it’s a struggle to find anything about programming with privacy in mind. We have a responsibility to keep users’ information private, so we need tools and techniques to ensure that privacy.
Finding data sets to train machine learning projects on can have unintended consequences. Any ML enthusiasts out there who can explain what to look for when choosing data sets?
If we’re honest, we could all probably use a talk on how to create bug reports that will actually result in fixes.
We clearly need a Python game arcade during the conference. I will happily bring a bunch of quarters if someone brings the games.
Python has been deployed to help during several recent emergencies. What’s it like to use Python in those scenarios? Is there anything you’d do differently or wish you had in your toolbox?
The National Oceanic and Atmospheric Administration has this lovely open data discovery portal. Let’s talk about the weather (especially the growing number of extreme weather events).
There’s one poster that I would love to see: a guide to what Python programmers are expected to know at different experience levels, at least in terms of what hiring managers are looking for.
Building a Python app can be a matter of hours — but scaling that same app could take the rest of your life. If you’ve gone through the process, please let the rest of us learn from your experience.
IoT / connected devices have enabled a lot of people to customize their homes to better suit their needs, like by using lights to create visual warnings for folks who can’t afford fully accessible alarms. Talk us through what that sort of project entails.
Given Python’s educational usage, we may need to spend more time on Python’s user experience. I’m not sure if this topic would be best as a talk or as an open space.
Several open source communities have experienced controversies over limiting the use of their work based on ethical concerns. It seems worth discussing what ethical concerns Python contributors have, as well as what Pythonic ethics might look like.
Using Python to change your online browsing experience (i.e., filtering out abusive content on reddit) could make for a great talk.
I would love to know how to effectively assess libraries and frameworks when choosing how to build a project. How do you vet tools so you avoid components that won’t be supported a year from now?
Can someone demo some hiring exercises that don’t require whiteboarding? Ideally those exercises can actually show an applicant’s Python skills without asking for an unreasonable amount of work, but I don’t want to be, you know, too optimistic.
We have about a decade left to make meaningful progress on climate change. Are there any projects out there that require Pythonic assistance? Talk us through the onboarding process and then maybe set up a sprint on that project.
I continue to maintain that not enough programmers are terrified by the words “intercalary periods.” Time zones aren’t anywhere near the only difficulties in implementing time into code worthy of a talk.
How we got to Python 3: I don’t think I’m the only one who likes a good code archaeology talk, so an overview of how Python has evolved over the past 20 odd years could be awesome.
Python for writers (fiction and otherwise) could be an awesome talk. I could see coming at this topic from a couple of different ways, like dissecting some of the scripts writers have shared on GitHub.
How to improve search in your projects, especially when you’ve scrapped a giant pile of websites, PDFs, or other data and that pile is just sitting there, silently judging you for not already working with it.
I’m sure someone out there is going to be running 2.7 for years to come, so talks about maintaining and using legacy code are great. If you’ve got any particularly well-aged code still in production, tell us about what it takes to keep that code working. (I have literally written a short story about the consequences of running 2.7 for far too long, so I’m obviously thinking about this topic a lot.)
Could someone with experience in anonymizing data sit us all down and talk about how to anonymize data and what potential issues we need to look out for?
Okay, I’m pretty sure that most conferences don’t want talks about gambling, but I did read an interesting paper about predictive modeling for horse racing and there’s definitely a talk in there. Maybe stay away from talking about betting and focus on the math and horses.
How to triage and understand Python code bases someone else wrote. Honestly, I could probably use some advice about understanding the code Past Me wrote, too.
How to do due diligence on an open source project before using it: There are definitely security factors we need to think about, but we also need to talk more about project sustainability and deciding if it’s worth supporting projects with questionable approaches to inclusion.
While a lot of us use GitHub, there are other version control apps out there (including other git-based options). When does it make sense to use other options for Python projects and is it important to reduce reliance on a single app?
Python in a hurry: what tools and techniques can help get something / anything into production? But you’ll also want to cover the tradeoffs and technical debt accrued along the way.
There are some serious pros and cons to doing genetic testing through 23andme and similar tools, so maybe it’s time to talk about how to do our own analysis of our genetic history (including using some of the Python tools that already exist in this area).
I know NASA uses Python and I just want to say that I am here for *any* talk about using Python to launch stuff into space. (Non-NASA space talks are also super cool.)
What’s the life cycle of a Python library? What should we know before we decide to create new libraries? (Bonus points if your slide deck illustrates concepts using the life cycle of a python!)
Benchmarking the different hosting options for Python-based projects would make a great poster session topic (and I would probably ask for a copy of that poster for my office).
A lot of programmers learn multiple languages, so where should a Python programmer start with other languages? I know a lot of folks say JavaScript, but I bet there’s a lot more to the discussion.
Software testing on a shoestring budget would be great. There have been a lot of “Python for activism!” talks lately, but one of the results have been some projects thrown over the wall without any testing, because testing seems hard and expensive.
Another technology archeology idea: what old hardware can you get running with a more modernish interface? And let’s go old-school: if you have access to, say, a Jacquard loom, what can you do with it with a modern programming language?
Building local mapping systems, especially in ways where data can be shared. As a for instance, being able to map warming shelters (especially the informal ones, like churches) as they open and close in real time would be so useful during freezing temperatures.
Anyone with a generative art project should write it up, in my opinion. First, because all conferences need more art. Second, because there is some AMAZING art coming out of human / tech combos right now.
Augmented reality is a thing right now. There are amazing museum installations (more art!), accessibility upgrades, etc. out there that we’re not seeing a lot of in talks yet. (I’ve seen several “I made an app for other techbros!” talks, so anything else really would be nice.)
One take on the standard “make your API actually useable” talk I’d love to watch: how to prep your API to work with platforms like IFTTT or Zapier. What does it entail behind the scenes and how many different ways do users find to break things?
Building Python tools for non-programmers would be a useful talk. I’ve seen a couple of great PyQt walkthroughs, for instance, that could really be followed up with another talk on how people actually use GUIs after they’re built, necessary upgrades, unexpected edge cases etc.
Oooh, someone could totally do a talk on code review best practices, especially around what parts can be automated and what bits a human needs to do. If you’ve got some ideas for adding empathy to code reviews (especially for the bits that are automated), that would be great!
There’s some really interesting technology built around religious needs (often with Python). For instance, some Orthodox Jewish business owners take down their websites for the length of the Sabbath. Kosher technology is fascinating and talk-worthy.
I’m so here for data spelunking talks, especially from data journalists. Had to go to absurd lengths with a FOIA request, munge together data sets from old scans, or otherwise work with dubious data? What’s your workflow?
Would someone please give a talk with “How to Teach Your Daughter to Code” as the first slide and “Exactly the way you’d teach your other children to code” as the second? You could follow it up with an actual talk or submit it as a lightning talk.
I’m not sure what the oldest Python code still in use is, but if anyone’s running software using, say, Python 2.0, what does it take to keep that kind of well-aged software up? Even better if you didn’t write the code initially and had to read the previous programmer’s mind.
There are tons of talks on building tools to track and improve health, but very few on tracking and improving mental health. I don’t believe for a minute that none of y’all are tracking mental health data on yourselves, so put in a talk if you’re comfortable talking about it.
If anyone is hardening systems using Python to prepare for natural disasters (or man-made disasters, as the case may be), that’s definitely a thing you should put in a talk on.
I’m always in favor of community-specific trainings about how to work with the community’s code of conduct. Ally and bystander training around PyCon’s Code of Conduct would be particularly nice.
Python has impacted how a bunch of other programming languages have evolved. A talk on those impacts in other languages, along with an exploration of anything those languages have improved upon would be super interesting.
There are entire series of books dedicated to using what you know about one programming language to learn another. What about a talk that uses the same approach to introduce a couple of Python frameworks? What do they have in common? How do they work differently?
How about an intro to building linters? Maybe some best practices, tips on making linters more accessible, that sort of thing?
An annotated discussion of all the Monty Python jokes in the Python language, especially for everyone who did not grow up with the antics of said comedians.
So you have 75 ideas to get you started and roughly a month to write your proposal. What are you waiting for?
During PyCon, I gave a tutorial on writing about Python. I’ve included my script below. You can also watch the full talk on YouTube, but be aware that it’s over 3 hours long if you don’t skip the exercises.
In this workshop, we’re going to learn how to effectively write ABOUT Python. We’re going to be talking about some general mechanics of writing about technical topics, as well as some Python-specific topics.
Major pitfalls in Python communication
Common Python audiences
Strategies for editing and testing content about Python
Writing opportunities in the Python community
We’re going to do several exercises to practice these strategies, although they may be a little different than the average workshop exercise at PyCon. We’re going to write prose, not code, so this may be a little different for some of you.
I’d also like to note some specific topics I’m going to cover that can be uncomfortable for some audiences. We’re going to discuss race, gender, ability, and age, along with ways Python community members have been marginalized.
Python Versus Prose
The Python community, as a whole, talks more about communication than many of our counterparts. My personal theory is that Python enjoys a special status in newsrooms. Part of that is Python’s use in data journalism. But I think Django’s development is the big factor: one of the most widely used Python framework came out of a daily paper.
Python, as a result, is pretty good about documentation. We’ve got decades of good examples to build from, as well as some tools that help us with writing prose as much as they help with writing code.
However, writing code in Python remains a different process than writing prose about Python. One of the biggest differences is in the needs of the audiences for each. The primary audience for Python code is the Python interpreter. Python is a format intended to be readable by machines. We talk about the readability of our code a lot in the Python community — more so than many other programming communities — because we value being able to understand our own code without mechanical intervention.
We value human-readable code because we, as humans, are responsible for creating and maintaining our code. Our future selves thank us for clear and understandable code: my future self is always happier when my past self makes future maintenance easier. But humans are still a secondary audience for Python code. Beyond an interpreter or a compiler, most human readers of any such code will have at least a passing familiarity with Python. Yes, non-programmers will see the code, but most of the people interacting with it will have a more technical background than the average reader.
Python’s Pitfalls
Over the course of working on The Python Style Supplement, I conducted both surveys and interviews about what books, blogs, and other materials members of the Python community read to learn more about the programming language. I also took the opportunity to talk to these folks about what problems they had with Python media — what issues made learning and using Python harder.
There are four issues that I heard and saw over and over again.
I’ll be going through a tutorial and it won’t work, because I’m running Python 3 and the tutorial writer used Python 2.7
The writer basically told me to go read the code
I keep trying to look up the difference between things like PyPy, PyPi, and PyPA
I can’t find anything written about a particular Python project
As writers, we want to avoid these pitfalls.
I’ve rewritten the four pitfalls here so that we can more easily talk about them from a writer’s perspective, instead of a reader’s.
Telling readers which versions of Python and other dependencies you’re using
Creating context for code. Even sample code isn’t self-documenting
Explaining and disambiguating the jargon that’s accumulated around Python
Getting resources to promote new writing, especially on open source projects.
We’re going to get much deeper into these pitfalls and how to avoid them over the next few hours.
I’m also going to add one more pitfall, based on my experiences writing about Python.
Setting expectations about what Python programmers know at different points in their careers
These are in no particular order, and I’m actually going to start with that last point.
Python Audience
When we’re planning what to write, we need to know who we are writing for. The Python community is not just one giant homogenous whole: even if we limit ourselves to talking about just Python skill levels, we’re still talking about a range starting with folks copy-and-pasting Python scripts without a clue of what they’re doing all the way through to folks who have advanced degrees in computer science.
Writing something useful to every Python programmer on that spectrum is hard — and rare. I’m a professional and I don’t bother most of the time. Instead, I write for smaller sections of that spectrums, sometimes rewriting the same material in different ways to make versions useful different audiences.
Talking about these differences in the abstract is hard. Let’s look at this in a more concrete way.
Python Personas
Here are a few different personas we can find in the Python community. These people are entirely made up, but we can talk about how they would respond to different types of writing.
Pat the Newer Python Dev
Piper the Experienced Python Dev
Nat the Nonprogrammer
Ruby the Experienced-in-Another-Language Dev
Darby the Decision Maker
There are, of course, plenty of other personas we could talk about, but this narrows down the field to a couple of key points. I actually use these personas in writing projects and have gotten to know these folks really well.
All of my imaginary friends here have back stories.
Pat is a recent programming bootcamp grad. They’re on the younger side. Pat loves Game of Thrones and will get every reference to that show you can squeeze into an article, but Pat can’t tell you the difference between Monty Python and the Mickey Mouse Club.
Ruby got started programming when COBOL was the hot new thing and hates all programming languages equally. Ruby reads XKCD and probably knows more about Python’s Easter eggs than Python itself. That’s going to change next weekend when Ruby is going to learn enough Python to pass a programming interview.
Darby gets to decide on whether to use Python to build new projects for their startup. Darby often has money to spend and has titles like VP of Engineering and CTO on their resume. Darby also loves football — but not American football. Darby doesn’t use the word ‘soccer’ because Darby works with team members all over the world and doesn’t want to confuse them.
I’m deliberately fuzzy about the race and gender of these personas. Personas aren’t a good tool for figuring out how to address gender, race, and other facets of identity. These personas are MY imaginary friends and they’re a product of MY experience. The furthest outside of my own experience I can go is letting Pat be a Game of Thrones fan, even though I’ve only seen a few episodes. Personas are most valuable when looking at work and educational experience. We will be covering strategies to ensure your writing is inclusive later on.
In the meanwhile, though, let’s talk about some characteristics we can assign to our personas.
Python Community Members
The Python Software Foundation’s survey of Python programmers is one of the best sources of information for personas. For instance, the 2018 survey found that 50 percent of Python programmers also use JavaScript.
I’m super confident that Piper, our experienced Python developer, is going to be familiar with JavaScript. Even if Piper doesn’t use JavaScript every day, we can assume a basic level of knowledge.
Pat, our newer programmer, might have JavaScript knowledge, but we’re going to want to add extra context and maybe even link to some resources. As it happens, Pat’s bootcamp curriculum was very thorough — but Pat still wants to know why Java has its own scripting language because even the most thorough curriculum is going to have to gloss over naming decisions made when Pat hadn’t yet started kindergarten.
We can make similar assumptions about Piper and Pat’s familiarity with popular frameworks and libraries in the same way.
These assumptions are as good as the data they’re based on. The PSF’s survey is based on self-reporting, so there are probably some folks it misses. But it’s still significantly better than other surveys of developers because the PSF works hard to get respondents from different backgrounds. In contrast, surveys of insular communities don’t give us particularly useful data. If you rely on Stack Overflow’s developer survey, you’d be working off of the assumption that 11 percent of programmers are women. There’s a gender disparity in programming for sure, but most programming communities are looking at closer to 24 percent women, based off of surveys conducted by Accenture in 2016.
Python’s Continuing Growth
Overall, the Python community continues to grow. Its expansion means we need to talk about what that growth means for our personas in the long run.
Our community is trending younger, which is great for the longevity of the Python programming language. But that also means that we’re getting more community members who associate Monty Python with their grandparents.
Our community is also trending more global, including programmers whose first language is not English. Only a fraction of Python writing happens in languages other than English and translations are not as common as anyone would like.
Both of these trends impact how we can write about Python. As more people use Python, we can’t assume everyone will have access to the same media or will get the same jokes. We need to think about the context these readers need, whether it’s an Easter egg explainer or an explanation of why a certain decision was made.
Humor is tricky when writing about technical topics. Jokes tend to need a lot of context. Even puns require knowledge about pronunciation. Jokes can also age your content faster than technical issues. One additional note about humor: think about who you are making fun of. Punching up is funny. I feel comfortable snarking about Monty Python because the members of that comedy troupe have made serious bank and have legions of fans ready to talk about the good points of their careers. Punching down is boring. If I want to watch someone make jokes at other people’s expenses or use humor to be a bully, I can just watch the news.
Monty Python’s 50th Anniversary
I’ve mentioned Monty Python in this talk a few times so far and we need to talk about it. When Guido van Rossum named the Python programming language, he was referring to Monty Python, not a snake.
Monty Python is a British sketch troupe who have turned 45 episodes made between 1969 and 1973 into a bunch of movies, books, games, a musical, and a few other things. This year is Monty Python’s 50th anniversary.
I’m making sure to describe exactly what Monty Python is, because we can’t assume that everyone using the Python programming language also is culturally fluent in Monty Python. That’s because Monty Python turns 50 next year. We might as well be asking programmers to get references to The Beverly Hillbillies, Petticoat Junction, or Green Acres. That in itself isn’t necessarily a problem, but some jokes age better than others. Monty Python isn’t aging particularly well.
By expecting Python programmers to be familiar with Monty Python’s body of work, we’re sending them to look up sketches with titles that include the N word. I don’t think any of us want to accidentally endorse something like that.
I’m not saying you can’t ever make a Monty Python reference again. I am saying we all have to consider the context of our references before slapping them on projects we want to share with the whole world. I’d ask you to think about it the same way you might think about putting a picture of an actual python in the middle of killing its prey upon your project’s homepage. No matter how cool all of you are with snakes, I am more interested in snake jokes and references than I am in snakes themselves.
Styles in Python
Within the Python programming community, we’ve established standard styles for code, as well as naming schemas, both formally and informally.
We have PEP 8, the style guide for Python code, which includes naming conventions for variables, method names, and such. It doesn’t specifically include suggestions for how to write prose, though some of its instructions are just as useful for prose as for code. PEP 8 prioritizes for readability and consistency in code. We can take those instructions to heart when writing.
We also have less formal systems, especially for project names. For instance, many Python conferences and user groups include the city they’re located in their organizational names. Geography is a relatively easy way to disambiguate different local communities from larger overarching communities. We can tell that PyLadies Atlanta and PyLadies Santo Domingo are two separate groups. It gets even easier because there are unique identifiers for different locations in the form of IATA codes. IATA makes sure airport codes are unique, since there are very important differences between Portland, Oregon and Portland, Maine, if only because my home is in Portland, Oregon. IATA’s codes are so convenient that sometimes cities use them as nicknames or identifiers. Not all cities’ IATA codes are exactly intuitive. Chicago airports, you better believe I’m looking at you right now. Those sorts of departures from style — these inconsistencies, if you will — often require explanations so that readers don’t get distracted from a tutorial by trying to figure out where the writer is from.
And while I will always struggle to remember that tickets to both ORD and MDW will get me to Chicago, the sort of “Py*” prefix used in PyLadies has become an easy-to-remember signal that we’re talking about Python. There are a variety ways “Py” has slid into Python project names, beyond just the prefix.
Some projects have chosen words whose letters already include “Py”, like Pyramid. “Pi”, spelled with an I instead of a Y, is pronounced the same way (at least in English), so there are also names that use nonstandard spelling like Project Jupyter. And then there’s the word “Pie”, which sounds like “Py” and is generally delicious. CherryPy, for instance, follows this naming schema.
A lot of projects have developed their own internal naming schema as well and for good reason. When related projects are branded together, users are more likely to realize that they can use all the different pieces you create. BeeWare, for instance, uses a combination of puns — so many puns — bees, and history, to create impressively descriptive names. First off, BeeWare has a subtitle, a full name, if you will. It’s BeeWare: the IDEs of Python. As in, what Julius Caesar was told in Shakespeare’s play of the same name, just before he was assassinated by a bunch of dudes in togas, except they’re referencing interactive development environments, rather than the middle of March.
As it happens, Toga is the name of a BeeWare library which provides wrappers for GUI APIs. Because of course, it is. Just like, of course, the name of BeeWare’s prevalidater is Beefore, with two Es.
If it sounds like I’m saying a lot of names, that’s because we name a lot of things. We name them pretty fast, too — fast enough that there are multiples sets of projects sharing a name. I’m willing to bet that most of us in this room have heard of Django, the Python-based web framework. But there’s also a piece of tablature software for musicians, also named Django.
Name collisions are annoying when you’re debugging a program, but they are a full on pain in the rear when you’re trying to search for help online. How many times have you walked away from a meetup or a conference with a Python module in mind to look up once you get home? You really only have three hopes for success for remembering the name: the project has a memorable name, your new contact remembers to forward you that link or you manage to find it through a search engine. You might wind up adding a bunch of keywords to your search terms, adding and removing words until you fight the right incantation to summon whichever library you’re looking for.
And if you’re looking for Python modules to help you with your herpetology research, I don’t even know what to tell you, except that I guess some herpetologists might have made the situation much more complicated by naming a species of python after Monty Python.
Name collisions are our future, by the way. Unique identifiers are hard and we keeping building new things we have to name. We need to get used to disambiguating between similarly named tools in our writing as a matter of course.
Disambiguation
Disambiguation is a fancy word which just means clarifying what you mean by a particular word — or name. If, for instance, I’m talking about Python, I’ll say Python, the programming language, not the snake. Just like spelling out abbreviations, you only need to disambiguate terms once in a piece of writing. You can even do it in a footnote if you’re the sort of person who likes footnotes.
When writing about a programming language with multiple versions, disambiguation becomes even more important. No one enjoys getting halfway through a tutorial before realizing they’re using the wrong version of Python or some dependency. There’s a really, really, really easy solution to this problem, though: NOTE THE VERSION OF PYTHON YOU’RE USING WHENEVER YOU WRITE ABOUT PYTHON. Even if you assume everyone you know is on Python 3, include the version number. Python 4 is mostly a glimmer in people’s eyes, but folks are starting to talk about what might be included when that version comes around. Similarly, there are not only people still using Python 2.7, but even earlier versions. If you only remember one thing from this workshop, please remember to include version numbers.
While some writers like using links for disambiguation, I’m not the biggest fan. I strongly encourage you to keep your disambiguation, and other necessary context, in your writing, rather than sending readers off with links. There are several reasons.
The first is that I’ve spent a lot of time writing content with marketing in mind. Whether you’re trying to sell a product or win over a new user, you never want to give up a reader’s attention. If you send a reader away, you may not get them back.
The second reason is that not everyone will be able to click links. Most of us are probably used to high-speed internet where we can access everything we need and download every package we see. The only time we really worry about downloading anything in advance is for workshops like this because conference wifi doesn’t always perform well.
But not all of your readers have that experience. I know a Python instructor living in Alaska who relies on satellite internet. When he travels outside of his home town, he downloads packages, updates, books — any large files he needs — because downloading these files at home is next to impossible. In the state of Alaska, around 15 percent of households can’t access internet faster than 10 megabits per second. You can technically watch Netflix with 10 megabits per second, but you’re not going to enjoy it.
Lastly, even if your readers have high-speed internet, links can break. Even if you’re maintaining and updating the content you write, preventing link rot is tough.
I’m also not the biggest fan of relying on search to provide context for similar reasons. Expecting readers to google topics doesn’t always end well… I’ve heard of readers winding up on Urban Dictionary pages, learning extremely non-professional definitions.
Clarity
When you’re writing about Python, you have one goal: writing as clearly as possible. While disambiguation is a major pitfall when writing about Python, it’s only one part of clarity. Whether you’re writing support documentation or tutorials, you need some other human to be able to apply those concepts after reading them. That means writing the clearest prose possible (and, if you’re anything like me, some ruthless editing to get rid of any fancy writing that creeps in along the way). Given our diverse audience, there are several tactics for ensuring clarity.
Choose a tone before you start. As a community, Python is fairly informal. There’s kind of a spectrum to formality, though. While informal tones are great for talks, when you need to relate with other people in the room, they’re less useful in documentation, where a personal tone can distract from key content.
Keep your sentences short. Especially if you’re sharing instructions, you want a clear and short statement containing one step (or concept). Short instructions are easier to follow, as well as to test.
Keep your tenses consistent. Check your verbs to make sure they all follow the same patterns — no jumping between the past, present, and future.
Keep adverbs and adjectives to a minimum. Along with bulking up sentences, too many descriptive words may distract readers from your content.
Explain antecedents — Keep your pronouns and the nouns they refer to clear. Those nouns that pronouns refer to are called antecedents and you never want them out wandering on their own.
Limit passive sentences. They’re often the longest sentences in a given piece of writing, they often rely on unclear pronouns, and they flop around waiting to trip up a reader. If you’re struggling to identify passive voices try adding the words “by zombies” to the sentence. For instance, consider this sentence: “The program was written to automate work flows.” I can add “by zombies” to the end and it still works. “The program was written to automate workflows by zombies” is a clunky sentence but it works. That means the sentence is passive voice and worth changing to something like “I wrote the program to automate workflows.” In comparison, “I wrote the program to automate workflows by zombies” makes no sense.
Be confident in your writing. Avoid phrases like “I think”, “probably”, or “most likely” as much as possible. This sort of wishy-washy language just gives readers doubts.
Clarity can kinda be measured. You may see suggestions that your documentation and other materials about technical topics should be written with an 8th-grade reading level in mind. Basing your reading levels on some abstract idea of what an 8th grader in the U.S. may be able to read may not provide useful context, but there are various tools (including built-in metrics for some word processors) that smush together data. If your only metric is graded reading levels, you’ll want to write to what your tool considers an 8th grade reading level. These tools are automated, though, and not exactly accurate.
For what it’s worth, this talk is closer to a tenth-grade reading level, because I use words like ‘disambiguation’ and ‘antecedent.’ Technical terms or jargon are usually considered more advanced, without a lot of consideration for whether you explain or contextualize those terms. Consider reading levels a rough guide.
Findability
Findability is just as important as clarity. No matter your use case, people have to be able to find your writing to be able to use it.
The question of findability overlaps some with disambiguation. We don’t want people researching ancient mystic oracle snakes when they search for Python, after all. And if you want to nerd out with me about the use of oracle snakes in ancient Greek, please see me after.
For some people, findability is roughly equivalent to search engine optimization, or SEO. With SEO techniques, you’re telling search engines how to find your material. Search engines are important, but since our actual readers are humans, we need to go further.
Use brand names correctly. Python, Django, AWS, and other brand names are recognizable. Making clever jokes or creating your own abbreviations for brand names almost always adds confusion.
Include error messages. Whether you’re writing about how to fix one specific problem or discussing how to trouble shoot several issues, include the error messages users may see along the way. People routinely google error messages in order to find solutions, which makes error messages useful for SEO. Error messages also let readers know right away if they’re looking at material that can help them with their specific problem.
Make your content skimmable. We also want to think about findability within each piece. Humans rarely read a whole document — we tend to want just the information we’re looking for. That used to mean looking at the table of contents and index, but indexes are far less useful for a digital document. When writing for screens, making your content skimmable and searchable is key. If you’re focused on writing clearly, especially in choosing words that will make sense to your audience, you’ll also be writing for findability. To make your writing more skimmable, you’ll want lots of headers and whitespace. If you’ve been coding in Python, you may already be excited about both whitespace and clear labels.
Differentiate code samples. While Python code tends to be pretty readable, most folks will need a visual cue that they’re reading code, rather than prose. That differentiation doesn’t have to be extreme — just setting code samples in a monospace font, rather than the font the rest of your writing is in, gets the job done.
Once people find your writing, you also need to convince them that you’re trustworthy.
Trustworthiness
Not all writers are trustworthy. I’m not saying that we’re a bunch of scammers, but rather that a lot of writers fail to earn the trust of readers.
Respect the reader. Patronizing or talking down to readers is a surefire way to lose those readers.
Respect the community. The Python community can feel huge, but it’s really quite tiny when we consider how interconnected it is. None of us know every other single Python user, but I’ll guarantee that most of us are familiar with the same authors, as well as leaders in different areas of the Python ecosystem.
Be informal (relatively speaking). Companies may need more formal tones, at least in copy, but being able to put a name and a face to a company can be really helpful. I can’t tell you how many software consultancy websites don’t have a single person mentioned by name anywhere on the site. A little personalization can help convince a reader that you know what you’re writing about. If you’re comfortable including a photo of yourself, do that too — you want readers to know that there’s an actual human expert behind your content.
Be consistent. Refer to technologies in a consistent fashion — even if it’s not the style other people use. Inconsistencies, even as small as writing PyLadies with a camelcase L versus writing Pyladies with only the first letter capitalized, can distract readers and make them wonder about the quality of the material they’re reading.
Make time for updating old content. Documentation rot is a thing, and once that sort of rot sets in, readers will be reluctant to continue using affected materials.
Include images, if you have any. I can send you a ton of studies that humans connect faster with visuals than the written word. But don’t just put a photo of a pair of hands on a keyboard. I invented that. In 2004.
Write inclusively. I’ve given a whole other workshop about writing inclusively about tech, but the TL;DR is that we have a responsibility to write material that doesn’t make readers feel unwelcome, whether through racist microaggressions, gender assumptions, or even the ability to access material in the first place.
Avoid obsolete terms. Technology moves fast and outdated material just isn’t trustworthy. This goes beyond technical updates, though. The Python community has mostly rejected terminology like “master / slave.” I don’t want to rehash the whole argument here, but there are two points I want to highlight: whether or not you feel comfortable using terminology like this, there are people who experience pain when they have to use terms that remind them of terrible experiences. Furthermore, slavery still exists today and diluting the meaning of the word “slave” makes it harder to work against the end of such practices. Second, language changes, constantly, and we should expect more changes.
Consider the word “literally” for a moment. When I tell you that I am literally freezing, you know I’m cold. But am I actually literally experiencing a concerning drop in my core temperature? Not so much.
Despite my own feelings on the interchangeability of the words “literally” and “figuratively” (and do I ever have some opinions!), the reality is that we haven’t just suddenly agreed to switch the meaning of a word out of nowhere. Different communities use different words in different ways. Language grows and changes to cover new concepts constantly, like how the word “computer” used to refer to a person making calculations, but now refers to a bunch of different types of devices. These changes are routine, through conversation, slang, academic use, memes, translation and literally every other time we communicate. There is a reason English has a reputation for rifling through other languages’ pockets for loose nouns!
Trying to stop the growth of language is like shouting into the wind. Even if it makes you feel better, it’s not effective. And, honestly, most attempts to control language come with a lot of elitist and biased crap. (The history of the word “ain’t” is a basically a primer on classism and language.) Instead, think about how you can stay up to date on how language is being used in the Python community by reading widely within the community and how to update your past writing when changes occur, even if you’re just going with “find and replace”.
The Checklist
I’ve just thrown a ton of information at you. I know from experience that it’s impossible to keep all of these considerations in mind when writing. But, luckily, we live in the future, so we don’t have to memorize this sort of stuff. Instead, we’re going to use a checklist.
When I’m writing and editing, I have checklists that I run through. I write an outline, then I check the list to see if I’m missing something. I write an incredibly bad first draft, then I check the list. I edit that draft into something useful, then I check the list. Why do I check it over and over again? Because I’ve edited out something absolutely necessary more than once and needed to go back and read that material. Checklists help me catch potential issues before they turn into real problems.
Python version number (and version numbers for dependencies, if appropriate).
Roughly an 8th-grade reading level (or another metric)
Up-to-date tech references (and if you ever work on a project for more than a couple of months, don’t be surprised if you need to go through and update these references more than once)
Get rid of passive zombies and unattended antecedents
Consistent style, especially when referring to brand names and sharing code samples
Eliminate huge blocks of text
Find visuals, if possible.
No wishy-washy language. Be confident in your knowledge.
Self-Editing
Some of the errors we caught probably would have been caught by an editor. Many of us don’t have editors, though: unless you’re working in a company with money to market their product, you’re likely responsible for editing your own work or relying on other volunteers in an open source project.
Self-editing is not enough, no matter how often we have to pretend that self-editing can catch every problem. So what do we do when we don’t have money to pay editors?
Get readers. If you’ve ever written or read fan-fiction — and I’m totally not calling you out either way — you may have heard of the concept of a beta reader. Beta readers go through a draft and tell you where they don’t understand something or struggle with an idea. While most of us aren’t writing Python fan-fiction, the same idea works.
You probably can’t ask one person to read everything you write and give you feedback. Even romantic partners need a break from reading your material. You want to build a list of readers you trust and who are likely to catch things you can’t. Your readers should also be folks who have the privilege of doing this work for free — not everyone can, and asking someone to take on work they can’t afford to do is not okay.
Your list of readers shouldn’t just include technical experts who can proofread Python as well as prose. You’re going to want to recruit readers in several categories.
Diversity + sensitivity readers. Sensitivity readers grew out of a practice in fiction writing where writers get specific feedback when writing about people or cultures outside of their own experience. But sensitivity readers aren’t just for fiction! They’re really useful for getting feedback on issues you don’t even know exist. For instance, until I worked with an editor of color, I hadn’t really noticed how often we code “black” as “bad”, such as “blacklist” or “black hat.” Those details may seem small, but they can be hugely impactful on how society as a whole sees Black populations.
Accessibility + test readers. There are so many mechanics that go along with publishing information that can prevent readers from using that information. We’ve already talked a little about how slow internet connections can make our writing inaccessible, but there are many different layers of accessibility. I just finished a project where I needed to ensure that readers with visual disabilities could fully access all materials. In print, that meant using larger type and specialized typefaces. In digital formats, that means making sure your material can be accessed by screen readers and other tools. Asking readers to test your work on multiple devices and platforms is one of the only ways to check your accessibility; while there are standards, a surprising number of websites and publishing tools don’t meet them.
Usability + technical readers. Having someone with equal or greater Python experience review your work for technical accuracy is always a good idea. But consider bringing in a reader who is less experienced as well. I’ve even brought in nonprogrammers to read programming materials because they can spot some errors more effectively because they don’t have any implicit knowledge about the topic. A person with a little distance from the project can also help you catch jokes that are hilarious to you but rely on insider knowledge. Sometimes those sorts of in-jokes confuse or exclude people, making it even harder to get up to speed with a new library. Feel free to ask your family to read over your writing, provided that they’re good at giving feedback. You can never guess who will run into what information and interact with it online. You certainly can’t control who learns about given technical topics — if you could, every member of my family would be banned from ever seeing the word “Bitcoin”. Your family members count as one person in this case, by the way. You can probably assume that your family’s background is close enough to your own that you’ll want to make sure to get some other opinions. Stakeholders. Even when we’re writing outside of commercial settings, we typically know other stakeholders in a project. Depending on what kind of project you’re working on, your stakeholders could include employers and their lawyers, project contributors, and all of your friends who listen to you talk about this project incessantly. That last group should be allowed to opt out.
Editors. Lastly, if you can, find the money to pay a professional editor, especially on big projects. It may cost less than you think — and it almost certainly costs less than making a mistake. A lot of editors aren’t in a financial position to contribute to open source for free, so money remains the best way to get them involved.
Persuading folks to work on unpaid projects is never easy. I’ve had some luck creating a sort of editing round robin for certain types of projects — like a group who all look over each other’s resumes and give feedback.
Whether you’re self-editing or working with other people, give yourself time between passes on your work. Even a day or two can make an article feel fresh. Read suggestions and edits before implementing them, as well. Taking criticism can be tough and giving yourself time to feel your feelings before trying to fix your writing will result in better changes.
Editing Tools
The best editing tools are those that have been in use for a while. Most of the bugs have been worked out of style guides, for instance. Style guides started at newspapers, covering details like how big headlines should be and how to correctly refer to government officials. Designers acquired the idea, creating design style guides with details like exactly what colors are in a company logo and and reusable style elements. Then developers got with the idea and created development style guides, like Python’s very own PEP8. PEP8 covers details like file naming and versioning conventions, along with style suggestions like including whitespace.
In terms of style guides for writers, we have plenty of options. My first love was the AP Stylebook, which is used by a lot of newspapers and other print media. Maybe I’m easily thrilled, but I adore style guides. They’re basically reference guides of just the information you need to work on a particular type of project. I actually make my own style guides just for funsies: not only am I the editor of The Responsible Communication Style Guide, but I also make style guides for basically every project I work on, whether it’s for a blog, a book, or documentation. I write down all the project-specific information, like how each participant’s name is spelled, along with the latest technical jargon, and all the other resources I know someone else will use.
You may have more than one style guide on your desk when working on a project. In fact, you *should* have more than one style guide. It’s a question of graceful deprecation — you need a project-specific style guide, but having an industry-specific style guide and a more general guide like The AP Stylebook or The Chicago Manual of Style.
It’s easy to build up a whole bookshelf of style guides. There are references like The Chicago Manual of Style, industry-specific style guides like The Bluebook which covers legal documents, organization-specific style guides like The Microsoft Manual of Style for Technical Publications. Depending on the project you may need more than one style guide — you might use an internal style guide when you’re writing documentation, then need to grab something broader to look up what your internal guide doesn’t cover. Sometimes you may need to even pull a more general guide off your shelf, like the Chicago Manual of Style. It’s a somewhat graceful deprecation, keeping the guidelines we need close at hand, with a fallback plan for anything an internal guide doesn’t cover.
Style guides are routinely updated, by the way. The AP Stylebook will definitely have more updates in the future, from new technology terms to updated discussions of sports statistics. In fact, that’s their entire business model: journalists are encouraged to buy a new copy every single year. Most of us only update our copies every couple of years, but we’re used to thinking about at least this one specific tool as something that needs to grow and change with the language it describes.
That assumption of change is really useful when we talk about how to improve the systems and tools we rely on. It provides a framework where we can find ways to do better, ways to update our expectations as we learn, ways to improve on our communications. Sometimes it takes more time than we like to make these changes. (It took the Associated Press until 2016 to agree with the rest of us that “internet” shouldn’t be capitalized.) As it happens, though, there’s nothing to stop you from opening up a text doc and writing your own style guide. I’ve been doing that for years, which led me pretty much directly to giving this talk.
There are plenty of startups out there who are excited to offer you some sort of cutting-edge automated editing tool. Grammarly and Hemingway are both pretty well-known. These tools are to spell-check as what integrated development environments are to Notepad.
That power doesn’t necessarily equal out to good advice, though. Hemingway, for instance, relies on rules created by Ernest Hemingway. Leaving all his other issues aside, Hemingway was a decent writer — but not everyone writes like Hemingway and Hemingway’s style doesn’t fit all use cases. For instance, Hemingway was opposed to all adverbs and most adjectives. But sometimes we need both adjectives and adverbs to fully explain a process, especially if we need to explain technical jargon. If Hemingway’s rules don’t work for you, that’s okay.
If you’re writing in a language other than English, there may be more effective automated tools. English, however, rummages for spare nouns between seat cushions. It’s a difficult language to analyze for the same reasons that it’s hard to learn: English is secretly a stack of three other languages in a trenchcoat just looking for norms to break.
Some of these tools also have dangerous flaws. Tools like Grammarly work by tracking what you’re typing. That means they’re keyloggers. By default, Grammarly’s browser plugin sees everything. Including passwords. Personally, I really like Grammarly and still use it, but I do so without keeping the browser plugin constantly active. In the short-term, though, expect automated editing tools to continue having quirks and issues.
Writing Tools
While a lot of tooling focuses on the editing side of things, there are a few writing tools that are effective. Templates are hugely helpful.
Just to disambiguate, I’m talking about about written templates: documents with blanks we can fill in like Mad Libs. I’m making a point to specify because I am not talking about templating engines.
There are some tools, like TextExpander, which can be used to fill in pre-existing templates on the go, but a lot of writing templates are just text documents with sections where you can put materials. I create a lot of templates for my work, because I do a lot of work that needs to be consistent. I also really hate staring at blank pages at the beginning of a project. If I have a basic template to fill in, I already have a starting point. For blog posts, for instance, I know I always want to end with a call to action — something that the reader can immediately do, which may or may not benefit me, depending on what I’m writing.
Calls to action are easy to template. My template is just three words: “Do the thing.” I know that I have to give readers a concrete action to follow, with a clear action verb. I’ll add context and detail as appropriate, but I always start writing my calls to action by modifying “do the thing.”
I generally don’t set out to make templates, by the way. Before I write a new project, I rummage through past projects for similar pieces that I can use as a template. Then I make a copy and delete all the bits I don’t need. If I find a particular template useful, I’ll clean it up and save it with the rest of my templates.
There are plenty of writing tools out there. Word processors are, of course, standard. A lot of writing tools are like time management apps, though: people tend to create tools that work perfectly for their specific use case. For someone following similar workflows, such tools can be useful — but if you have a different workflow, such tools can be tough.
Scrivener, for instance, is a big fan favorite for writing long documents. It’s got a slew of features for keeping track of references, reorganizing chapters, and so on. I can’t use it. My workflow just doesn’t match up, because I look for feedback at multiple steps of my writing process. I’m also all about the brain dump, rather than a strictly outlined approach. In fiction communities, by the way, this debate is often referred to as ‘outlining versus seat-of-your-pantsing,’ meaning that you just start writing and see where you wind up. I do think of myself as more of a pantser.
Writing workflows are intensely personal, so don’t be surprised if the new hotness doesn’t make your writing process any easier. Try out tools, of course, but you’ll probably get more writing done if you’re writing, rather than trying out tools.
Lightning Talk Submissions
We’re going to try out a template now. This template is for lightning talk proposals. I’ve ran lightning talks submissions at a couple of conferences, as well as given plenty of lightning talks myself. I got over wanting to craft that perfect individual proposal around the time I gave my second lightning talk.
This template covers most of the information you can be asked for when prepping a lightning talk. It’s not entirely universal, but it’s enough to fill out just about every lightning talk submission form I’ve seen.
Talk proposals have to be persuasive: anyone submitting wants to speak and you need to make sure your proposal stands out. I know that templates can seem like a weird tool in situations where conformity isn’t useful, but once you get into using this particular template, I think you’ll find that a template lets you focus on writing persuasively, rather than trying to make sure you dot every i and cross every t.
So who is the audience for a talk proposal? It’s not the folks who will hopefully be listening to you speak. Rather, it’s the person who approves or rejects talks. Keep that in mind for filling out this template. It’s kind of a secret, but certain details in your proposal aren’t exactly carved in stone if you get accepted.
Let’s go over this really quickly and then we’ll take a few minutes to each write our own proposal.
Name + email address. In your own template, you can just add this information and not update it.
Short bio. By short, I mean maybe two lines. These two lines need to demonstrate that you’re a great person to give this lightning talk. For instance, if you want to give a lightning talk about Python, your bio might mention what you do with Python.
Talk title. I know it’s tempting to be super clever here. I want you to resist the urge, because sometimes the folks deciding on lightning talks skim titles and then decide which proposals to read more deeply. You want something really straightforward and clear, so that your talk gets thr0ugh the initial review process. This, by the way, is one of those details not carved in stone. I routinely will fancy up the title of a a talk when I’m making slides, especially if I can think of something that will appeal to my audience.
Talk description. This is where the magic happens. Because lightning talks are short, this section doesn’t need to be long — but it does need to be interesting. If you have some big reveal in your talk, include it in the proposal. Don’t leave reviewers guessing about whether or not you’ve got something interesting to say. And I promise reviewers almost never give away a good twist ending.
The big idea / takeaway: What, exactly, do you want your audience to learn during your talk?
By the way, just following directions and filling out submission forms completely will put you ahead of a surprising number of other potential speakers.
I’m going to give you a few minutes to fill this out. If you have an idea for a lightning talk, awesome!
If you don’t have any lightning talk ideas on tap, don’t stress — you can propose a talk about why a new programmer should choose Python over another programming language. We’re talking about the writing here, not the content of that writing.
Python’s Valuation of Writing
Python and Django both boast amazing documentation free to anyone with an internet connection (and some without). Creating that documentation was perhaps easier because of the availability of a cohort of programmers and documentation writers trained in communication.
We can’t assume, however, that all Python projects will start at newspapers or other media companies. In order to maintain the high documentation standards in this community, technical writers, programmers, and other Python contributors need communication resources. In order to build and maintain these resources, we need to talk about money.
Writing about Python is work; on the same level as coding the software, designing the interface, or testing its security. In an ideal world, every software development team would include at least one technical writer. While this isn’t an ideal world, the costs of documentation, particularly in Python, may not be insurmountable.
The Python community’s commitment to open source obviously impacts the finances of anyone choosing to work on Python projects, as well as how Python projects (as well as organizations using Python) can generate revenue. Most projects need at least enough revenue (through donations, sales, or whatever) to cover maintenance costs, relying on contributors to subsidize labor costs by providing their own time for free. But providing labor for free (at least under capitalism) can limit both a project’s growth and contributors’ abilities to meet their own needs.
The result is a set of financial patterns seen throughout the Python community:
Offering limited documentation for free, while charging for access to full documentation
Offering paid training
Offering paid support beyond documentation
Writing educational materials for larger publishers
Hosting installations of free software
These approaches to raising revenues have met with variable success in the Python world. In particular, charging for access to full documentation is controversial. Open source advocates consider free and accessible documentation a core tenet of any open source project. As Jacob Kaplan-Moss put it, “There’s a particularly pernicious anti-pattern in documentation where tutorials are provided for free but the real documentation is only available for purchase. At best that’s lazy and sloppy; at worst it’s downright evil. Free software needs free documentation. If you’ve got otherwise you should be ashamed of yourself.”
Evil may be a strong word but the reality is that there are plenty of organizations that have figured out how to fund open source work without charging for documentation. For instance, Django’s documentation is available for free, while many community members rely on paid training to pay the bills.
But that’s not necessarily enough to meet the needs of Python’s growing community. No matter what position you find yourself in, I encourage you to advocate paying writers and editors. Whether you can get money out of the marketing budget to pay bloggers, out of technical budgets to pay documentation writers, or out of diversity and inclusion budgets to pay sensitivity editors, every little bit will help us continue to create amazing free materials for the Python community.
Furthermore, be a good citizen of the Python community, especially when it comes to writing and editing. Support other writers and make sure they get credit for their work. Be empathetic when you see typos — and send a pull request to fix those typos when you can. Don’t ever be a jerk to someone writing documentation for free. Being a jerk about a typo may mean the difference between a documentation contributor staying in the community and leaving.
Writing for Other People
So far we’ve mostly focused on writing and editing on our own. But one of the joys of belonging to a thriving open source community is that we can work with *other people*. Sometimes, we can even get paid writing work!
But we do need to know how to play nicely with others to access those opportunities. So what opportunities are there to write about Python?
Talks: Writing talks to deliver at PyCon and other conferences
Documentation: Document software you or other folks have created. Documentation, by the way, is often suggested as a great entry point for new contributors who aren’t confident in their technical skills. That’s a little like having an intern handle social media, in my opinion, but that is an entirely different soap box. While documenting open source projects is usually a labor of love, many companies will happily pay documentation writers, both as employees and on a contract basis.
Blogs: You may have your own blog or website, but there are loads of different websites running material about Python. The PSF blog, for instance, welcomes guest posts and hires freelance bloggers. There are also loads of websites looking for both written and video tutorials, which tend to get premium rates when compared to articles.
Books: I am not necessarily recommending you write a book, especially if you’re doing it for the money. I’ve written several books and I don’t think I’ve earned enough to cover my time in sales from any of them. That said, if you have a book inside you bursting to get out, there are loads of publishers with Python lines. Maybe see me after if you’re considering putting in a book proposal soon — there are definitely some publishers I would recommend working with over others.
When you’re writing different materials about the same topic, it’s worth noting that you can repurpose material. If all your writing is focused on Python, you may be able to create new work with less of an upfront investment.
For instance, if I was pitching a Python book right now, I’d write somewhere between ten and twenty really in-depth blog posts, and then edit them into more of a book format. You usually can’t use the same material word for word — that’s considered self-plagiarization in a lot of circles — but you can use the same information and the same format to make something new.
Aside from getting two projects for maybe 1.5 times the work, this approach gives you material to persuade editors and publishers, along with conference content committees, to take you more seriously. If you’ve got published blog posts about a topic, you’re an expert in that topic. You may not be the most knowledgeable expert in the world on that topic, but the research necessary to write a bunch of blog posts is far more research than most people have done. It makes you a known quantity, with proof that you can write about that topic. Most editors and publishers will want to see samples of your writing before committing to a project anyhow, so you might as well make those writing samples do as much work as possible.
A lot of sites that routinely publish freelance or guest writing will have other requirements as well. Luckily, they’ll often share these details so that we can easily review them and submit our writing. These submission guidelines can vary from a few sentences and an email address to a fairly elaborate document laying out not only writing requirements but publication-specific styles.
OpenSource.com Submission Guidelines
Let’s take a look at the submission guidelines for OpenSource.com. Their guidelines are pretty detailed, which makes them relatively easy to write for.
They tell us the technical details of how they want writers to submit work — where to send articles, which file formats to use, and so on. In general, you don’t ever want to deviate from these instructions.
They give us a site-specific style guide so that we can make sure we get tone and formatting correct.
They tell us what kind of articles they’re looking for, including how long those articles should be.
They tell us some information about our audience, explicitly pointing out that some of the site’s readers are newer to technology. I’d probably use Pat’s persona to figure out how to write this article, because Pat generally matches up with this description. I do think we can assume that Pat has a little bit of Linux experience, even if they aren’t primarily Linux users.
They tell us how the material will be licensed. If you’re concerned about reusing material or getting paid for it, pay attention to what rights you’re assigning to a publisher. In this context, a Creative Commons license makes sense.
They also tell us about their backlink policy. Because a lot of folks use guest posting as a way to manage their ranking in search engines, a lot of publishers have become very careful about how they handle links. You’ll see this sort of policy much more often on sites that don’t pay writers, because most people don’t write without getting at least a little something out of it.
I do have to point out that a lot of websites would much rather hear your idea for an article and then help you develop a draft, rather than receive a mostly complete article. Personally, I prefer not submit full articles to sites I’m not already familiar with — OpenSource.com is a known quantity and I trust their editors not to be jerks, but there are editors and publishers out there who will take advantage writers who are willing to write without a confirmed acceptance.
One of the reasons that we’re looking at OpenSource.com is that one of their editors is attending PyCon and is actively looking for folks to write for the site about Python. OpenSource.com doesn’t pay contributors, but if you can afford to write without pay, it can be a beneficial place to get a byline.
The other reason is because we’re going to write short articles right now, using all the stuff we’ve been talking about.
Let’s Write Something
Exercises that reflect what you’ll experience are always better than something that can only mimic reality. Our last exercise today is going to be writing an article that meets these guidelines from OpenSource.com. I am going to add a couple of additional constraints to make sure we can both practice the skills we’ve covered as well as make enough progress in the time we have left for me to give you personalized feedback.
For this exercise, you’re going to describe a Python library and explain its value. Try to pick a library you’re familiar with because we don’t have a lot of time to devote to research. This sort of article meets the requirements for OpenSource.com’s for 500 to 600-word articles. However, I don’t expect you to write a full 500 words before we wind down this tutorial.
Even if you identify as a pantser and you like to just dive into writing, I’m going to ask you to outline what you’re going to write. They don’t have to be complicated, but they’ll help us discuss what your article might entail if you hit 500 words. Your outline should answer three questions:
What’s an example of how this library has been used? We’re talking real world examples here.
What do I need to know to be able to use this library?
How is this library better than competing libraries?If you truly can’t find any competition even by googling, you can tell me that instead.
Pat the Newer Dev needs you to answer these questions before they can decide whether learning about this library is worth their effort.
Don’t worry too much about getting spelling and grammar absolutely correct. This is your first draft and I’d normally suggest doing at least a quick editing pass before handing it over to someone else, but we only have so much time. I promise that all of my first drafts are terrible and that I won’t judge you.
Conclusion
Remember how I was talking about reusing and repurposing your material? As it happens, 500 words is about the right length for a 4 or 5 minute lightning talk. Y’all have just written lightning talks (though you might need to tweak language in order to give it as a lightning talk) discussing a specific library. Nice, right?
As we wrap up, I have just a few last things to say. First, writing is one of those skills that you can only build with use. The best way to improve your writing is to write as much as possible. The second best way is to read as much as possible, preferably from a wide variety of sources. The more time you spend with language, the better equipped you’ll be.
Also, in case I haven’t said this enough times, ALWAYS ALWAYS ALWAYS include version numbers.
Lastly, I want to point out a couple of great resources on writing:
Jacob Kaplan-Moss wrote a blog post series about writing about Python in 2009. The series may be ten years old, but it’s still a good resource. (https://jacobian.org/2009/nov/10/what-to-write/)
The Responsible Communication Style Guide and the Python Style Supplement
Sin and Syntax by Constance Hale is a book I strongly recommend if you want to learn more about writing prose outside of the context of the Python community
Write the Docs has videos online of years worth of talks about writing and they tend to be really good. As you’re looking for ways to level up after this workshop, watching these videos can be really helpful.
Content notes: codes of conduct, colonization, natural disasters, ageism, racism, interpersonal violence, actual snakes
I gave this talk at North Bay Python. I’ve included the text of the talk below, as well as the video.
Names matter.
Names set expectations: a conference with a location name in its title is probably in that location and a Python module with the word “test” in it will do something to do with testing. If North Bay Python took place south of the Bay, we’d all have some questions for the conference organizers.
Names create first impressions. Just reading the name of a project can immediately tell someone whether they’re going to use or contribute to that project. I’ve seen plenty of offensive library names and I’ve decided not to use those libraries just because of their names. I don’t need to look for a code of conduct or at the quality of the code of a project with an offensive name. I just move on. If you really want examples of those names, talk to me privately because I frankly don’t want to say them in public.
There’s a business case against using software modules with problematic names, if you work in the sort of organization that requires a business case to do the right thing: any core maintainer unable to respond to feedback about a problematic name will be unable to consider security risks that don’t impact them directly.
Names endure. Think about where we are right now. Petaluma. Sonoma County. California. The United States of America. The US got its name during the American Revolution. It was purposely structured to make a bunch of colonies sound like they were all working together and knew what they were doing. California is named for a magical island in a 16th-century Spanish romance novel. So, yeah, we use a name from a bunch of Spanish conquistadors thinking fondly of the love stories they read growing up.
Sonoma and Petaluma both come from Coastal Miwok words made to sound more acceptable to the Europeans who colonized this area. Sonoma’s root word means “Valley of the Moon”. Péta Lúuma was the name of the Miwok town located roughly here prior to the area being controlled by the Spanish, the English, the Spanish again, the Russians, the Mexican Empire, the Mexican Republic, the California Republic, and the United States.
Most dialects of Miwok are now extinct, due to the US’s genocidal policies with some European help. Before 1579, Coast Miwok tribal land included all of Marin County plus southern Sonoma County. By 1817, the only land still directly controlled by the Miwok was the Pacific Coast of the Marin Peninsula, from Point Reyes north to Bodega Bay. In 1920, Miwok and southern Pomo tribes tried to move to the 15 acre Graton Rancheria, held in trust by the federal government, but only 3 of the acres were actually habitable. The US government dissolved that trust in 1958 and ended federal recognition of the tribe until the Graton Rancheria Restoration Act was passed in 2000.
The name “Petaluma” endures.
Humans relate to names in deeply emotional and often unnoticed ways. Let’s go to natural disasters for a potentially less depressing example: researchers at the University of Michigan looked into whether people are likely to donate to hurricane aid causes if they connect with the hurricane’s name. Folks who shared a first initial with the hurricane’s name were significantly more likely to donate. That means that Kelly’s, Kai’s, and Khadija’s were more likely to donate to relief efforts for Hurricane Katrina than Hurricane Mitch.
Correlation isn’t causation, but I will guarantee you that there is someone out there thinking about how much money they could raise by choosing a hurricane naming schema with a distribution of first initials more closely matching the distribution of first initials of all our names.
Names don’t exist in a vacuum. Making sure we understand the context and nuances of potential names is a necessary first step.
Python Naming Schema
Question for the audience: Who here knows what inspired the name of the Python programming language?
Monty Python — that’s right!
Monty Python is a British sketch troupe who have turned 45 episodes made between 1969 and 1973 into a bunch of movies, books, games, a musical, and a few other things.
I’m making sure to describe exactly what Monty Python is, because we can’t assume that everyone using the Python programming language also is culturally fluent in Monty Python. I have heard: “Monty Python? I think my grandparents used to watch that.”
That’s because Monty Python turns 50 next year. We might as well be asking programmers to get references to The Beverly Hillbillies, Petticoat Junction, or Green Acres. That in itself isn’t necessarily a problem, but some jokes age better than others. Monty Python isn’t aging particularly well.
By expecting Python programmers to be familiar with Monty Python’s body of work, we’re sending them to look up sketches with titles that include the N word. I don’t think any of us want to accidentally endorse something like that.
I’m not saying you can’t ever make a Monty Python reference again. I am saying we all have to consider the context of our references before slapping them on projects we want to share with the whole world. I’d ask you to think about it the same way you might think about putting a picture of an actual python in the middle of killing its prey up on your project’s homepage. No matter how cool all of you are with snakes, I am more interested in snake jokes and references than I am in snakes themselves.
Within the Python programming community, we’ve established some standard naming schemas, both formally and informally.
We have PEP 8, the style guide for Python code, which includes naming conventions for variables, method names, and such. It doesn’t include suggestions for how to name projects, though there is a little piece of advice I’d love to have engraved on something shiny: avoid names that include the lowercase letter “l”, uppercase letter “O”, or uppercase letter “I”. I think that these suggestions should be followed for more than just single character variable names. They just make names easier to read and retype.
We also have less formal systems, especially for project names. For instance, many Python conferences and user groups include the city they’re located in their organizational names. Geography is a relatively easy way to disambiguate different local communities from larger overarching communities. We can tell that PyLadies Atlanta and PyLadies Santo Domingo are two separate groups. It gets even easier because there are unique identifiers for different locations in the form of IATA codes. IATA makes sure airport codes are unique, since there are very important differences between Portland, Oregon and Portland, Maine, if only because my cats are in Portland, Oregon and they expect me to fly to the correct city today in order to feed them dinner. IATA’s codes are so convenient that sometimes cities use them as nicknames or identifiers . Not all cities’ IATA codes are exactly intuitive. Chicago airports, you better believe I’m looking at you right now.
And while I will always struggle to remember that tickets to both ORD and MDW will get me to Chicago, the sort of “Py*” prefix used in PyLadies has become an easy-to-remember signal that a module is meant for use with Python. There are a variety ways “Py” has slid into Python project names, beyond just the prefix.
Some projects have chosen words whose letters already include “Py”, like Pyramid. “Pi”, spelled with an I instead of a Y, is pronounced the same way (at least in English), so there are also names that use nonstandard spelling like Project Jupyter. And then there’s the word “Pie”, which sounds like “Py” and is generally delicious. CherryPy, for instance, follows this naming schema.
A lot of projects have developed their own internal naming schema as well and for good reason. When related projects are branded together, users are more likely to realize that they can use all the different pieces you create. BeeWare, for instance, uses a combination of puns — so many puns — bees, and history, to create impressively descriptive names. First off, BeeWare has a subtitle, a full name, if you will. It’s BeeWare: the IDEs of Python. As in, what Julius Caesar was told in Shakespeare’s play of the same name, just before he was assassinated by a bunch of dudes in togas, except they’re referencing interactive development environments, rather than the middle of March..
As it happens, Toga is the name of a BeeWare library which provides wrappers for GUI APIs. Because of course, it is. Just like, of course, the name of BeeWare’s prevalidater is Beefore, with two Es.
If it sounds like I’m saying a lot of names, that’s because we name a lot of things. We name them pretty fast, too — fast enough that there are multiples sets of projects sharing a name. I’m willing to bet that most of us in this room have heard of Django, the Python-based web framework. But there’s also a piece of tablature software for musicians, also named Django.
Name collisions are annoying when you’re debugging a program, but they are a full on pain in the rear when you’re trying to search for help online. How many times have you walked away from a meetup or a conference with a Python module in mind to look up once you get home? You really only have three hopes for success for remembering the name:: the project has a memorable name, your new contact remembers to forward you that link, or you manage to find it through a search engine. You might wind up adding a bunch of keywords to your search terms, adding and removing words until you fight the right incantation to summon whichever library you’re looking for.
And if you’re looking for Python modules to help you with your herpetology research, I don’t even know what to tell you, except that I guess some herpetologists might have made the situation much more complicated by naming a species of python after Monty Python.
Name collisions are our future, by the way. Unique identifiers are hard.
Name Selection
As we’re choosing names for Python projects, we have to keep all of these things in our head. Because that seems like an easy way to manage such a big decision, right? Nah, I’m just joking, that sounds super hard.
I actually just went over all of that stuff with you so that I could go over this checklist:
Check for how this name may be used elsewhere
Talk to actual humans about the name and what it means to them
Maaaaaaaaybe talk to a lawyer
Listen to the actual humans, no matter whether they respond positively or negatively
Make sure you can get any necessary accounts
Write down the meaning and history of your project’s name before you forget about it
In short, we’re going to go through a due diligence process before finalizing a name for a new project. Some of these steps can happen in different orders, but I want you to check off every item on this list before buying another sweet domain name.
And if you’re worried that these rules will eliminate all the good domain names, rest assured that isn’t an issue. Let me put it this way: despite following these steps, I still own way too many domain names.
Check for how this name may be used elsewhere
Checking how a particular name is used can be as simple as running some online searches. Start with Google or DuckDuckGo or whatever flavor of search engine you prefer. Go a couple pages deep into those results. Depending on the words you’re looking at, you may get a Wikipedia disambiguation page, which honestly does a lot of the work here for you. On a practical level, we want to make sure there isn’t a major module out there already under a name you want to use. Wikipedia tends to be more up-to-date about programming modules than a lot of other topics.
Do the same on Twitter, and click around to all those tabs that show up on the search page. You can look at what tweets mentioning your keyword are the most popular, usernames which include the keywords and so own. I’ve found that this is one of the easier ways to check both newly evolving words and to surface name collisions in other languages.
Go to Urban Dictionary, too. Before you actually type things into search boxes, though, I should definitely point out that Urban Dictionary is routinely NSFW. Twitter is also routinely NSFW, but for entirely different reasons. In this use case, you’re looking for NSFW terms that relate to your name — things that you may be too mature to respond to, but that other users would giggle at or find offensive. As such, maybe don’t assign this job to an intern or first-time contributor.
Basically, we’re looking for any terrible ways a bored thirteen-year-old can twist your project name. We can’t preempt every comment, but we do not have to make it easy.
Talk to actual humans about the name and what it means to them
Next, and this is probably the hardest part, I’m going to need you to talk to actual humans, starting with any stakeholders interested in whatever project you’re working on. Depending on what kind of project you’re naming, your stakeholders could include employers and their lawyers, contributors (including documentation writers, who will need to type that name over and over again until it loses all meaning), and all of your friends who will have to listen to you talk about this project incessantly.
You’re going to also want to check in with your potential users about your name. Spend just as much time on talking to potential users about naming as you do on more visual user experiences. Check how they spell the name when they hear it for the first time. Check how they pronounce it if they read the name before hearing it. This might sound like a marketing exercise, but it’s really a question of usability and accessibility. If a user can’t figure out how to spell a product name, they’ll have to deal with a high level of friction before even deciding whether learning about a given tool is worth scrolling.
Tempting as it may be to ignore asking anyone outside of tech, I want you to make a point of running of names past at least three people who don’t work in tech. If you’re headed home for a holiday visit, feel free to ask your family to talk to you about your name idea. You can never guess who will run into what information and interact with it. You certainly can’t control it — if you could, every member of my family would be banned from ever seeing the word “Bitcoin”.
Your family members count as one person in this case, by the way. You can probably assume that your family’s background is close enough to your own that you’ll want to make sure to get some other opinions. You want to talk to folks who come from backgrounds different than your own because they’ll help you predict responses to that name from more people.
Personally, I like to ask a kid about any names I’m considering. At the very least I will immediately hear any possible poop jokes about my name selection, long before any adult will work up the courage to discuss possible scatological references.
A person with a little distance from the project can also help you catch names that are hilarious to you but rely on insider knowledge. Sometimes those sorts of in-jokes confuse or exclude people, making it even harder to get up to speed with a new library. If you can’t explain the joke in the time it takes us to walk to wherever we’re eating today, your sense of humor may be too subtle for the rest of us.
One more note about humor: think about who you are making fun of. Punching up is funny. I feel comfortable snarking about Monty Python because the members of that comedy troupe have made serious bank and have legions of fans ready to talk about the good points of their careers. Punching down is boring. If I want to watch someone make jokes at other people’s expenses or use humor to be a bully, I can just watch the news.
Check in with folks who speak languages you don’t, along with speakers of different dialects. Python is used all over the world, in more than 150 countries, so you’re never going to be able to check against all languages, but do what you can.
Maaaaaaaaybe talk to a lawyer
Occasionally, a lawyer may be useful in this process. I am not a lawyer and therefore all I can say that there are very few situations in which I would personally feel the need to consult a lawyer before finalizing the name for a new project. It’s pretty much just edgecases, like wanting to use a name already claimed by a multinational corporation. Future Thursday may hate me for this, but any smaller legal issues are her problem. Do your own risk assessment, though.
Listen to the actual humans, no matter whether they respond positively or negatively
Why is listening a separate step? Because we don’t just want first impressions. We want to know what sort of connections endure. We want to know about those jokes that take people a minute to remember. We want to hear any “Oh crap do you know what that sounds like?” moments.
Make sure you can get any necessary accounts
On a purely practical level, you’re going to need to know if you can get domain names, GitHub repos, or any other accounts you might use. If you’re reusing a name that’s already been associated with one software project, you’re going to have to do a little extra running around before you can finalize your name.
Very few platforms have a system for aging out old accounts yet, so there’s no clear date when any software project is permanently inactive. Some open source projects go years between releases, with no real need to update a website or a Twitter account in between. You have to use your best judgement.
Check the old project’s materials for trademarks, copyrights, and other indicators of intellectual property. No matter how any of us feel about intellectual property laws, I think can assume none of us really want to get sued. It’s not impossible to unravel intellectual property from a defunct project. I have never found a name I consider worth that level of effort.
Luckily, since we’re already talking to humans, we can just add the person last known to be running a given project to the list: if there’s a maintainer listed or even a contact form, just reach out and ask what’s going on with the project. If it’s actually defunct, ask if you can have their domain names and platform accounts. Make it as easy as possible on the other person and offer to pay for any fees, like domain transfer fees.
Even if there isn’t a pre-existing project, domain names can be tricky. Anyone working on anything related to any of the items on that Wikipedia disambiguation page could have already bought the domain name you want. Luckily, most Python projects are targeted towards audiences familiar enough with the internet to not flinch at the sight of non-dotcom domain names, like .io. That opens up options. Options for more research, I mean: That domain name is assigned to a part of the Indian Ocean currently referred to by the name British Indian Ocean Territory. Previously, that area was known as the Chagos Islands, mostly to the Chagossians, who the British forcibly removed from the Chagos Islands in 1966. Oh, look, another terrible example of how names reflect colonization! Using a .io address means taking this information into account.
Write down the meaning and history of your project’s name before you forget about it
Lastly, PLEASE PLEASE PLEASE document at least a little information about your project’s name. Just stick it in your README or some other piece of your documentation where it’s easy to find. Your documentation is a great place to put information about your project’s name and why you chose it.
Write down the pronunciation of the name that you use, even if you think it’s obvious. If you really want to know why I started working on a Python-specific style guide, it’s because of PyQt. That’s four consonants in a row, just hanging out. I’m pretty fond of vowels, so I wasn’t sure at first how to pronounce PyQt. I googled it, but I did not have a lot of luck.
Address any potential issues right away. Make a note of what other uses of the project’s name that you’ll need to disambiguate from. Django documentarians might make a note about music, for instance, so that someone creating a Django plugin meant to be used by musicians will pick a name that will actually be searchable. Address any potential problems head on, as well. Including context about a location name, for instance, will let you make sure people know which Portland you live in.
Go ahead and tell any jokes that go along with your project’s name right there in the documentation. Humor is amazingly memorable, but we only get that memory boost when we get the joke. It’s okay if not everyone gets the joke at first — jokes are still funny after they’re shared.
Takeaways
Names matter, even names that have existed for hundreds of years
Maybe don’t use Monty Python as a key part of your naming conventions
This text was the basis of my recent talk at Write the Docs NA 2018, mostly about the glory and greatness of creating your own style guides from scratch. It highlights some of the major lessons I’ve learned about writing style guides, because I really like style guides — like, a lot. I make style guides for my own personal projects which only I will ever work on. I also help make style guides for wider use, including The Responsible Communication Style Guide. My current project is a style supplement for people writing about the Python programming language, so you will almost certainly hear me complaining about disambiguation if you run into me in person.
I believe I’m among fellow style-guide enthusiasts if you’ve read this far, but let’s just go over a couple of givens for this article. First, style guides are amazing. They’re basically lists of style decisions your team needs to stick to while working on a project that you no longer have to keep in your head. When you’re writing with a team, sharing a style guide will help ensure you all write with a similar style. Readers won’t get confused by different spellings, editors don’t have to correct the same errors over and over again, and writers can eliminate internal debates about when to capitalize the word “internet”. Style guides aren’t limited to written content, either — there are design and coding style guides as well.
It’s easy to build up a whole bookshelf of style guides. There are references like The Chicago Manual of Style, industry-specific style guides like The Bluebook which covers legal documents, organization-specific style guides like The Microsoft Manual of Style for Technical Publications. Depending on the project you may need more than one style guide — you might use an internal style guide when you’re writing documentation, then need to grab something broader to look up what your internal guide doesn’t cover. Sometimes you may need to even pull a more general guide off your shelf, like the Chicago Manual of Style. It’s a somewhat graceful deprecation, keeping the guidelines we need close at hand, with a fallback plan for anything an internal guide doesn’t cover. Those internal style guides are mostly what we’re talking about here — though I still have more space on my style guide shelf if any of you are thinking about something bigger.
Making your own style guide is a relatively easy process. RCSG started as a list of notes I kept for my own writing and then shared with a couple of other people as a template to adapt for their projects. That list turned into a book because it just kept getting longer. You too have the power to create your own style guide deep inside of you. I have faith in each of you.
A lot of developing a style guide is exactly what you think it is. You make a list of what you want to cover in your style guide, maybe words that you need to make sure you capitalize correctly or a list of the colors you should avoid for buttons. You keep adding things when you hear a new suggestion or make a novel mistake. Personally, most of my style guides are just a list of errors I’ve already made and reminders to not make them again. Seriously, I’ve already got a list of errata to update for the next printing of the RCSG because I’ve made new and interesting errors since the book went to the printers.
You edit your list, realize you’ve missed some things, edit again. You ask some people to read it and give you feedback, then you incorporate that feedback. At some point, you’ve got something you’re ready to share with a broader audience. Consider that version a first edition, because style guides are not carved in stone. You’ll start a list of things you want to update in the next version the moment you print a single copy, too. It’s not too different from other process documentation.
There’s no secret sauce when it comes to creating a style guide. You make the tool you need. There’s no magic software that will automagically pluck words from your documentation and shove them into a style guide. You can get the job done in a text file if that’s the only software available to you (though I encourage you to learn from my mistakes and move your style guide out of your word processing software of choice before it’s longer than five pages). A style guide can live within your other documentation or be available separately, depending on what you need.
The mechanics of putting together a style guide probably already feel familiar and I don’t want to spend too much time on them. Let’s talk about the major issues that come up when creating a style guide instead. There are three key sticking points we’re going to cover here:
Questioning assumptions
Bringing in unheard voices
Providing tooling and education
Question your assumptions
Sometimes I think that writing documentation is just a constant process of asking people to break down one step into smaller and clearer pieces. Everyone assumes that certain knowledge is universal. But unless we can develop species-wide telepathy, we can’t make that assumption. Every reader who looks at a piece of documentation brings their own experiences to interpreting it and may interpret it in an entirely different way.
That’s doubly true when working on a style guide. We can’t assume how other people use language. Consider the word “literally.” When I tell you that I am literally freezing, you know I’m cold. But am I actually literally experiencing a concerning drop in my core temperature? Not so much.
Despite my own feelings on the interchangeability of the words “literally” and “figuratively”, we haven’t just suddenly agreed to switch the meaning of a word out of nowhere. Different communities use different words in different ways. Language grows and changes to cover new concepts constantly, like how the word “computer” used to refer to a person making calculations, but now refers to a bunch of different types of devices. These changes are routine, through conversation, slang, academic use, memes, translation and literally every other time we communicate.
We can’t assume we know what someone means when they say “literally” anymore, at least without context. We need to ask.
I would go into a whole bit about user research here, but Jen Lambourne already said everything I was going to say, plus quite a bit more, so I’m just going to refer you to Jen’s talk at Write the Docs 2018 and keep talking specifically about style guides.
Ultimately, the more you can question your own assumptions around the meanings of the words you’re trying to define, the better equipped you’ll be to create style guides that speak to everyone. Jargon, acronyms, idiom, and slang may all have their place in writing — especially within technical writing — but only as long as they improve our ability to communicate.
Examine the status quo
That’s a side benefit of creating a style guide to share with other people, by the way. To create a good style guide requires asking questions about the status quo. If your documentation is all in advanced technical jargon, developing a style guide is a chance to ask why. If there isn’t a reason, style guide development will also offer an opportunity to make some changes to the way your organization communicates.
Many people won’t argue with a style guide once it’s established. I would never encourage any of you to use this fact for evil. For good, though? It’s an opportunity to advocate for changes to the status quo. When you’re making or updating a style guide, you get to choose whether to capitalize the word “Internet.” You also get to choose how members of your organization refer to people, what metaphors are considered inappropriate in your materials, and whether images must have alt text tags. Each of these decisions is an opportunity to create a more inclusive organization as much as a way to coordinate the voice of your organization.
Of course, you should go through all the appropriate approval channels before implementing a style guide, and of course, you should work with your team to make sure decisions are acceptable to as much of your organization as possible. You can adapt and update your style guide as appropriate for your organization.
But that one dudebro in your office who refuses to give you input during the process and then wants to know what they can do to change the whole style guide after the fact? Yeah, for that dudebro, your style guide has already been sent out to be chiseled in stone. Sorry, dude.
I should also warn you about the danger of swinging too far in the opposite direction. While requiring writers to match an organization’s voice and style makes sense, style guides are not meant as ways to police other people’s tone or voice. There is no one true way to write in English and we should only attempt to describe how to use language in our own context. We need to empower writers to do better. It’s never our job to tell people they’re writing incorrectly At best, I’d consider any attempt to enforce particular ways of writing or speaking to be classism. At worst, doing so is a well-established and particularly destructive method of colonization. It also results in bad writing.
So, yeah, writing a style guide is more responsibility than it might look on the surface. Pulling together lists of words and styles isn’t nearly as hard as understanding the impact of a style choice. We have an obligation to take extra care when developing style guides, especially those intended to be used by a diverse audience. We need to balance the voice of the organization with the voice of the writer. We can clarify how we communicate, without policing other people’s writing in a problematic way.
Bring in unheard voices
Empathy is the best tool we have for building effective style guides. We need a lot of compassion in this process, too. We need compassion for our users — the people who will use this style guide to write documentation — but we also need empathy for our users’ users — the people who will read the documentation our users write. Finding enough empathy may be the hardest part of writing a style guide.
Hopefully, you can find compassion for fellow writers, whether they write documentation full-time or write on top of other responsibilities. To empathize with your readers, you need to make sure that you have an understanding of the many backgrounds your readers may come from. I’m not just talking about understanding if someone has the technical know-how to get through your documentation. I’m talking about understanding cultural context around the words we use and repurpose for technology. I like the example of the Chevy Nova. According to urban sales legends, the Chevy Nova sold poorly in Latin American markets because “Nova” means “doesn’t go” in Spanish. Snopes has disproved this story, but I still use it because all of the actual examples I could use require content warnings.
We’re all aware that listening is a key skill for documentation. We know that we need to listen to as many people as we can who create, consume, or otherwise interact with the materials. But there are still voices we can learn from who we fail to hear. We need to listen to programmers with dramatically different backgrounds. I know how to write for the 20-something dudebro with a computer science degree, but I don’t know if the same materials will work for a single parent trying to learn to code in between taking care of kids. The only way to learn is to listen to people who are not in this room. If we want to build a truly inclusive industry, we need to meet the needs of people who haven’t been able to join us yet. We need to go out and find them.
You won’t be able to ensure your style guide is all things to all people. Starting with the intent to listen, and iterate on feedback on as it comes in is the right place to start, though. Include the people you already have access to — as many editors, sensitivity readers, beta testers, and users as you can practically manage — and build on that base to include new voices as you find them.
Pro tip: Inclusion during the development process also gives other members of your organization a sense of ownership and improves the likelihood they’ll use your style guide when it’s complete. It’s nice when doing the right thing makes your life easier.
Empower community members
And, of course, what’s the point of a style guide that no one uses? I feel like there should be a good punchline here, but there’s not really a joke. There’s no value in a style guide no one will use.
The best style guides empower their users. In my ideal world, I could hand anybody a style guide and some workflow documentation and they’d immediately be able to contribute to a writing project. That might be a little utopian, but it’s not as far off as you think. Consider Wikipedia. The site’s Manual of Style is somewhat buried, but the editing FAQ is a mini-style guide, covering things like link formatting and how to write article summaries. It’s more than enough to get someone started on their first Wikipedia edit. The Wikipedia Editing FAQ is a gateway style guide. It empowers people to make immediate changes.
Honestly, you’ll know your style guide is top-notch when someone outside of the docs team can hate-edit inaccurate documentation without needing to talk to an editor. I can tell you from experience that most style guides and contributor onboarding systems are not at this level.
Provide education and tools
Ultimately, a style guide should democratize the writing process in your organization. Style guide users should be able to write more clearly without relying entirely on editors or experts.
That’s a big “should.” There are a lot of assumptions there — and since we’re questioning our assumptions, we need to unpack that “should.” All other things being equal, a style guide should democratize the writing process in your organization. Those other things are the tricky part, though. We can’t just hand people a tool and assume everything will be fine. We need to educate our communities on how to use those tools.
Planning for education needs to be a part of your style guide development before you ever look up your first acronym. For experienced documentation writers, that education may mean a short workshop on the specifics of *this* style guide, while other users may need more of a “Style Guides: How do they Even” class. Ideally, someone should be able to pick up a style guide and use it without a class but given that very few people seem to read style guides all the way through, personal walkthroughs is a really good idea.
I like to start my educational plan with materials on how to contribute to new iterations of the style guide, by the way. The more people who can add to and improve a style guide, the more the workload is spread out, which isn’t exactly altruistic but is a necessary practicality.
If you can create a culture of contribution for your style guide from the start, you’ll enable improvements you can’t imagine ahead of time. Go beyond writers, too — if you’ve got a developer who needs to write at least some of their own documentation, giving them access to your style guide files can let them build tools that work for them (and that might work for you, too).
Don’t fall into the trap of thinking of a style guide as a book or a handout. Digital style guides put information in a wider variety of hands and create a world of potential right now, from providing a basis for new kinds of linters to upgrading spellcheck to something far more useful. Imagine how great the future will be if we make all of our style guides available via API!
Move the Overton window
Style guides represent the future, whether we know it or not. They streamline production processes and give people power to work on their own projects.
They also give us the opportunity to talk about how we write and why. Those discussions have the power to change the world. Style guides offer a clear indicator of how an organization wants to discuss different questions. A style guide that cautions users against terminology that some readers will find offensive is an explicit Overton window. An Overton window is a guide to what we consider appropriate to share in public discourse. For example, women wearing pants in public was considered highly inappropriate — until the Overton window moved as more and more people decided pants are perfectly reasonable apparel.
Our communities, both technical and not, are facing big questions about what we want to look like in a year, in five years, in ten. Within technology, many of these big questions are about inclusivity. Some communities have hard-coded styles of communication that exclude everyone who hasn’t personally written a programming language. Some communities want to make sure that the benefits of technology are available to everybody. The ways we style materials dictates, in part, what side of the divide our organizations land on. The more tools we have to create inclusive documentation and other materials, the faster we can move the Overton window towards expectations of respect and inclusion, at least within our own organizations.
I’m not expecting anyone to go back to work just to lead a style guide based-revolution (though if you want to, I’d love to hear about it). I am hoping, though, that you’ll start thinking about how you style your own work and whether a style guide will help your organization communicate more effectively.
I’m hoping you’ll think about the cultural assumptions that go into a style guide and how to give a voice to more people in your organization.
I’m hoping you’ll think about the communication status quo on the projects you work on and whether that status quo is effective.
I’m hoping you’ll drive big conversations about the future of our communities and how to welcome more people to those communities.
To sum up: style guides are awesome.
You should make at least one style guide in your life, if only so I have more people to commiserate with, I mean talk shop with.
When you’re making style guides, consider the assumptions you make, how you can empower the people who will use your guide, and what you hope the future brings, at least in terms of communication.
Lastly, making a style guide is an awesome responsibility. It gives you the opportunity to guide conversations, defeat miscommunications, and maybe even inspire newcomers to your communities. Subtle, yes, but style guides are powerful — and with great power comes great responsibility.
This talk was given at AlterConf PDX. You can see a video of the talk here:
I want to talk to you about the word “literally” for a moment. When I tell you that I am literally freezing, you know I’m cold. But am I actually literally experiencing a concerning drop in my core temperature? Not so much.
Despite my own feelings on the interchangeability of the words “literally” and “figuratively” (and do I ever have some opinions!), the reality is that we haven’t just suddenly agreed to switch the meaning of a word out of nowhere. Different communities use different words in different ways. Language grows and changes to cover new concepts constantly, like how the word “computer” used to refer to a person making calculations, but now refers to a bunch of different types of devices. These changes are routine, through conversation, slang, academic use, memes, translation and literally every other time we communicate. There is a reason English has a reputation for rifling through other languages’ pockets for loose nouns!
Trying to stop the growth of language is like shouting into the wind. Even if it makes you feel better, it’s not effective. And, honestly, most attempts to control language come with a lot of elitist and biased crap. (The history of the word “ain’t” is a basically a primer on classism and language.)
We make plenty of tools to help us write and communicate, from linters to dictionaries. We create tools to make sure we get job titles and other details right. But those tools can be tools of oppression. When a journalist relies on references recommending obsolete, oppressive, or offensive terms as standard, they’re going to use those terms. It’s the easiest option, just like using someone’s deadname is easier than researching and respecting someone’s identity. Their audience will use those terms or approaches, too, because an authority just used them. There’s a ripple effect when we rely on tools created without considering their use and impact.
We can see this in actual examples from actual tools: There’s a particularly awful example that The AP Stylebook updated last year. While “child prostitute” or “teenage prostitute” used to be acceptable under AP style, in 2016 the guide was updated to suggest that writers avoid using the word “prostitute” for anyone under the legal age of consent. That’s because the word “prostitute” implies a sex worker who is “voluntarily trading sex for money” and someone under the age of consent, by definition cannot voluntarily participate in sex in the first place, according to Tom Kent, one of the editors of The AP Stylebook.
The AP Stylebook will definitely have more updates in the future, from new technology terms to updated discussions of sports statistics. In fact, that’s their entire business model: journalists are encouraged to buy a new copy every single year. Most of us only update our copies every couple of years, but we’re used to thinking about at least this one specific tool as something that needs to grow and change with the language it describes.
That assumption of change is really useful when we talk about how to improve the systems and tools we rely on. It provides a framework where we can find ways to do better, ways to update our expectations as we learn, ways to improve on our communications. Sometimes it takes more time than we like to make these changes. (It took the Associated Press until 2016 to agree with the rest of us that “internet” shouldn’t be capitalized.) As it happens, though, there’s nothing to stop you from opening up a text doc and writing your own style guide. I’ve been doing that for years, which led me pretty much directly to giving this talk.
Writing about people is hard and I’ve messed up more than once. I’ve learned a lot of what I know at the expense of the people I’ve written about, because the tools I relied on were crap in one way or another. I started keeping a pre-publication list of everything I need to double check on every project because I misgendered an interview subject I only knew through email. I made an assumption and pushed publish. A few hours later, I got an incredibly kind email from that person pointing out my error. I apologized, but that wasn’t enough. I never want to make that error again, so I added a step to my workflow to ensure that I’ll do better.
I try to do good work, but I’m sure I’ll make more mistakes in the future. When I do, I’ll apologize and try to find a way to do better. That, as Kronda has told us, is the job.
For me, part of that process has been creating The Responsible Communication Style Guide. Basically, I wanted to take all of my tools and tricks and put them in a reference manual so I could improve my own work. Then I realized that sharing this sort of guide could help a couple of my fellow writers avoid making similar mistakes and that I could do some research to answer some questions I still had.
Then — and this is the most important thing — I realized that writing this style guide by myself would be a huge mistake. Just like the top-down approach at organizations like the Associated Press, writing everything would be a way to guarantee that I got something else wrong. If we want to guarantee that our work is inclusive, thoughtful, and responsible, we need to create it in inclusive, thoughtful, and responsible ways. Sure, I had a list of questions, but I didn’t have useful answers.
But I sure wasn’t going to ask anyone to work on fixing MY writing for free. So I worked with The Recompiler to run a Kickstarter. We met our goal mere hours before our campaign ended, giving us enough money to pay contributors and cover printing costs. That’s basically it. Folks, do not expect to get rich writing style guides.
But we did pay our contributors! That’s one of the pieces about this project that makes me the happiest. One of the most wonderful feeling in the world is to say, hey, you, you’re awesome and you know stuff and would you please take this money right now? I strongly recommend it when you need a serious pick-me-up. Keep this recommendation in mind, though, because I’m about to have some feelings up here.
Usually I have to talk about my work in a way that will convince everyone in the audience that they should pay for me to keep doing it. But in this room, I see people who not only have done that (thank you!) but who have helped me to do work that I consider important. That makes me feel like I have a certain amount of freedom here. So I want to say a couple of things in conclusion.
I don’t think I’m the right person to have edited this style guide. I’m just a person who had the willingness and the time to do so. Focusing on this work, running a Kickstarter to fund it, and not relying on this book as my main source of income is incredibly privileged. I’ve tried to stay aware of that privilege throughout the process of making The Responsible Communication Style Guide a reality. The most effective strategy I’ve found is paying contributors, so that people other than me can afford to work on this project. It’s not a solved problem in any way, though, just like everything else about this project. We had several potential contributors who weren’t able to work on this project because we couldn’t pay enough to make this project a top priority.
I want to acknowledge that I don’t consider The Responsible Communication Style Guide complete. I have lists of improvements to make in upcoming editions, topics we need to add, and experts I need to pay. The first edition is just that. It’s a first iteration to at least give us a starting point to improve upon as we learn more and try new approaches.
Given that we live under capitalism, the standard solution to both of my concerns is more money. I have to admit that I’m not optimistic about either capitalism or getting money for important work right now. Several communities I love are shutting down or scaling back right now, because there’s so little cash to be had. Even this conference today is bittersweet because I know there’s only one AlterConf left after this.
For the organizations that have the most money to give, things like diversity and inclusion aren’t a priority. When a inclusivity project can’t raise for $10,000 from an organization that spends that much just on “unisex” t-shirts, there’s something wrong. Sure, there are always organizations looking to buy diversity and inclusivity indulgences, but they don’t put money into it in the long-term.
You’re in this room. You probably already know all of this. But I want to ask you to do something when you go back to work next week. Go ask your employer to spend some money, preferably from outside some poorly-funded D-and-I initiative. Do the same thing next week, and the week after. Look at technical training budgets, continuing education credits, even the budget for holiday parties. Look for ways to move that money into the hands of people doing good work.
Helping plan a party? Pick a catering company operated by a person of color.
Need CE credits for a professional certification? Check if there are CE trainers for your certification focused on accessibility.
Got a technical training budget? Choose the trainers who subsidize community work with technical training.
I’m not asking you to seize the means of production, but I am asking you to redirect the means of production every chance you get. I know that isn’t a particularly inspiring message, but it’s the one I’ve got right now.
On that cheerful note, the last thing I want to do while I’m up here is acknowledge all of the people who have worked on The Responsible Communication Style Guide. I can’t name all of you in the time I have left, but I want to thank Audrey Eschright, our publisher, as well as our contributing editors Stephanie Morillo, Ellen Dash, Heidi Waterhouse, Melissa Chavez, and Anat Moskowitz, along with our designer, Mel Rainsberger. I may have done most of the cat-herding on this project, but there literally would not be a book without these people.
I gave this talk at Write the Docs this morning and wanted to share my slides. They’re embedded below, but you can grab a PDF here and a link to a video of the talk here.
While APIstrat is an interesting conference (I’m always up for learning about amazing technical advances) I feel like a tsunami is approaching. I can sense it and I’m just waiting to hear the sirens go off.
But most of the other folks at APIStrat seem to feel like they’ve caught the edge of the big wave and they can just ride it down. There’s this sense that the entire concept of APIs are well established in the world; that the developers we work with are coming up with ever-increasingly brilliant ways to use our APIs and that all that is left do is create a few more APIs for a few more developers.
And, yet, most of the APIs we’re talking about touch surprisingly few lives. It’s rare to even hear about an API used to streamline the process of applying for veterans’ benefits or to improve the cash flow of the bodega on the corner.
APIs don’t have a trickle-down effect that we can rely on to help reach those people being left out of this new evolution of work. Without concerted effort to bring more people to the table, we can’t assume that we’ve done everything possible to truly disrupt the organizations that came before.
Part of this problem is a question of diversity — when most developers have shared worldview, seeing the missing pieces of the API puzzle is difficult. When you’ve never gone through the process of applying for food stamps, you can’t really come up with a way to make that experience work better.
Waiting for someone to fix the diversity numbers in the tech industry isn’t going to move us any closer to that tsunami. The underlying issue there is not that women and other marginalized groups don’t have access to STEM education (at least in the US), it’s that we keep entering the industry and keep facing uncomfortable situations where the only healthy option is to drop out of tech and do something where we won’t face as many micro aggressions, unequal hiring efforts, or doxxing attacks.
Before you ever start working on an API, you truly need to ‘get out of the building,’ to steal a phrase from Steve Blank. There are a wealth of opportunities out there for developers who step outside of their own worldview and examine what people who are far different from you need in their day-to-day lives. The business case should be obvious (if your API is a utility, selling access to it is a piece of cake), but you should also think about the opportunity to leave the world a little better than you found it.
Furthermore, think about how absolutely simple you can make using your API. Frankly, building on top of a good API shouldn’t require programming skills. IFTTT is a good example of what can be done in that direction, but there are also plenty of ways to create sample apps that just require someone to figure out a little copying and pasting in order to adapt to their own lives.
We have a chance to get this right. We have a chance to build a fundamentally better world — a place I’d love to live in — but we have to actively pursue doing the right thing. We cannot wait for every single person on the planet to learn to code. We cannot hope that they’ll scratch their own itches, because there’s no chance in hell of that happening.
Spend time around people who are very different than you. Volunteer for organizations that bring you into contact with people who don’t own computers. Work with homeless shelters, the Boys and Girls Club, and anyone else who needs a little help.
Build a network outside of tech. Find people who you can run ideas by, as well as get ideas from, when you’re deciding what to build next. Look as far afield as you possibly can. Make sure that those people can use your API on some level, even if it’s just through a little web app you throw together for that purpose.